上下文缓存
提示词缓存(Prompt Caching)可以减少重复输入内�容的 Token 计费,适用于多轮对话中固定的 system prompt、长文档分析等场景。
工作原理
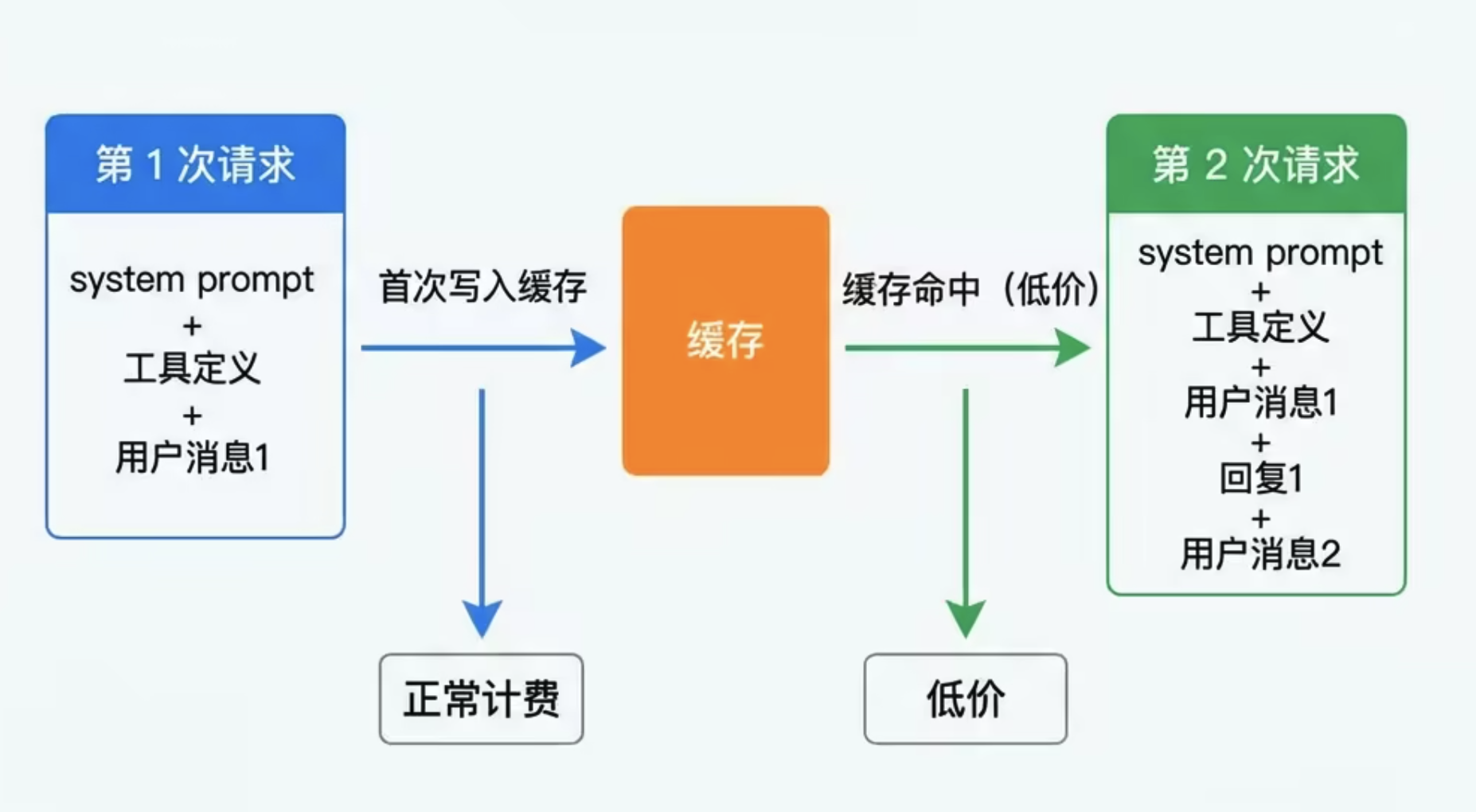
在多轮对话中,每次请求都需要携带完整的历史消息,这意味着固定不变的内容(如 system prompt、工具定义、长文档)会被反复计费。
提示词缓存的核心思路:对于请求中重复出现的前缀部分,只在首次写入时全价计费,后续命中缓存时大幅降低费用。
支持的协议
CloudBase AI 通过 Anthropic Messages API 协议支持提示词缓存:
| 协议 | 缓存支持 | 说明 |
|---|---|---|
| Anthropic Messages API | ✅ 支持 | 显式缓存 + 自动缓存 |
| Chat Completions API | — | 不支持客户端缓存控制 |
| CloudBase SDK | — | 不支持客户端缓存控制 |
备注
使用 Chat Completions 协议或 CloudBase SDK 时,服务端可能有内部缓存优化,但客户端无法显式控制。如需精确控制缓存行为,请使用 Anthropic Messages API。
使用方式
- 显式缓存
- 自动缓存
在需要缓存的内容块上添加 cache_control 标记:
curl "https://<ENV_ID>.api.tcloudbasegateway.com/v1/ai/cloudbase/v1/messages" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_API_KEY>" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "hy3",
"max_tokens": 1024,
"system": [
{
"type": "text",
"text": "你是一个法律条文分析专家。以下是一份完整的合同规范(共 5 万字):...",
"cache_control": {"type": "ephemeral"}
}
],
"messages": [
{"role": "user", "content": "请找出关于违约金的条款"}
]
}'
第一次请求会将 system prompt 写入缓存,后续相同前缀的请求将命中缓存,大幅降低 Token 费用。
在请求体最外层声明 cache_control,系统自动识别重复的静态前缀进行缓存:
curl "https://<ENV_ID>.api.tcloudbasegateway.com/v1/ai/cloudbase/v1/messages" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_API_KEY>" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "hy3",
"max_tokens": 1024,
"cache_control": {"type": "ephemeral"},
"system": "你是一个专业的天气查询助手。",
"tools": [
{
"name": "get_weather",
"description": "获取指定城市的实时天气",
"input_schema": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
},
"required": ["city"]
}
}
],
"messages": [
{"role": "user", "content": "今天北京天气怎么样?"}
]
}'
自动缓存适合多轮对话场景,系统会自动判断哪些前缀内容可以缓存。
检查缓存命中
通过响应中的 usage 字段判断缓存状态:
{
"usage": {
"input_tokens": 350,
"output_tokens": 120,
"cache_creation_input_tokens": 4200,
"cache_read_input_tokens": 0
}
}
| 字段 | 说明 | 计费 |
|---|---|---|
input_tokens | 未被缓存的输入 Token | 正常价格 |
cache_creation_input_tokens | 本次新写入缓存的 Token | 约 1.25x 正常价格 |
cache_read_input_tokens | 本次从缓存读取的 Token | 约 0.1x 正常价格 |
判断逻辑:
cache_creation_input_tokens > 0:首次写入缓存(略贵于正常计费)cache_read_input_tokens > 0:命中缓存(仅 10% 的正常价格)- 两者都为 0:未使用缓存
适用场景
| 场景 | 缓存收益 | 说明 |
|---|---|---|
| 长 system prompt 复用 | ⭐⭐⭐ | 几千字的角色设定、规则说明 |
| 长文档分析 | ⭐⭐⭐ | 将文档放入 system,多次提问 |
| 固定工具定义 | ⭐⭐ | 每次请求都带相同的 tools 列表 |
| 多轮对话 | ⭐⭐ | 前面轮次的历史被缓存 |
| 单轮短对话 | ⭐ | 无重复前缀,收益有限 |
缓存失效条件
以下情况会导致缓存无法命中:
| 条件 | 说明 |
|---|---|
| 内容变更 | 缓存的前缀内容必须精确匹配,任何一个字符的差异都会导致 miss |
| 工具定义变更 | 修改了 tools 列表中的任何字段 |
| 缓存过期 | 缓存有 TTL(通常为 5 分钟),过期后需重新写入 |
| 超过断点限制 | 显式缓存最多支持 4 个 cache_control 断点 |
提示
为最大化缓存命中率:
- 将固定内容(system prompt、工具定义)放在消息列表最前面
- 避免在固定内容中插入动态信息(如当前时间戳)
- 保持工具定义的稳定性
成本优化示例
假设你的应用有一个 4000 Token 的 system prompt,进行 10 轮对话:
不使用缓存:
每轮输入费用 = 4000 × 正常单价
10 轮总费用 = 4000 × 10 × 正常单价 = 40000 × 正常单价
使用缓存:
第 1 轮 = 4000 × 1.25(写入缓存)
第 2-10 轮 = 4000 × 0.1 × 9(读取缓存)
总费用 = 5000 + 3600 = 8600 × 正常单价
节省约 78% 的 system prompt 费用。