微搭 AI+ 执行动作
微搭中集成了具有 AI+ 能力的执行动作,帮助开发者快速搭建具有 AI+ 能力的低代码应用。我们提供了以下执行动作:
- 调用大模型对话:调用大模型,进行对话,支持流式和非流式调用
- 调用 Agent 对话:调用 Agent 进行流式对话
支持一键将生成的文本赋值到变量中,并提供处理完整 SSE 事件的能力。
使用示例
调用大模型对话
本小节我们将演示如何使用「调用大模型对话」执行动作。
配置大模型
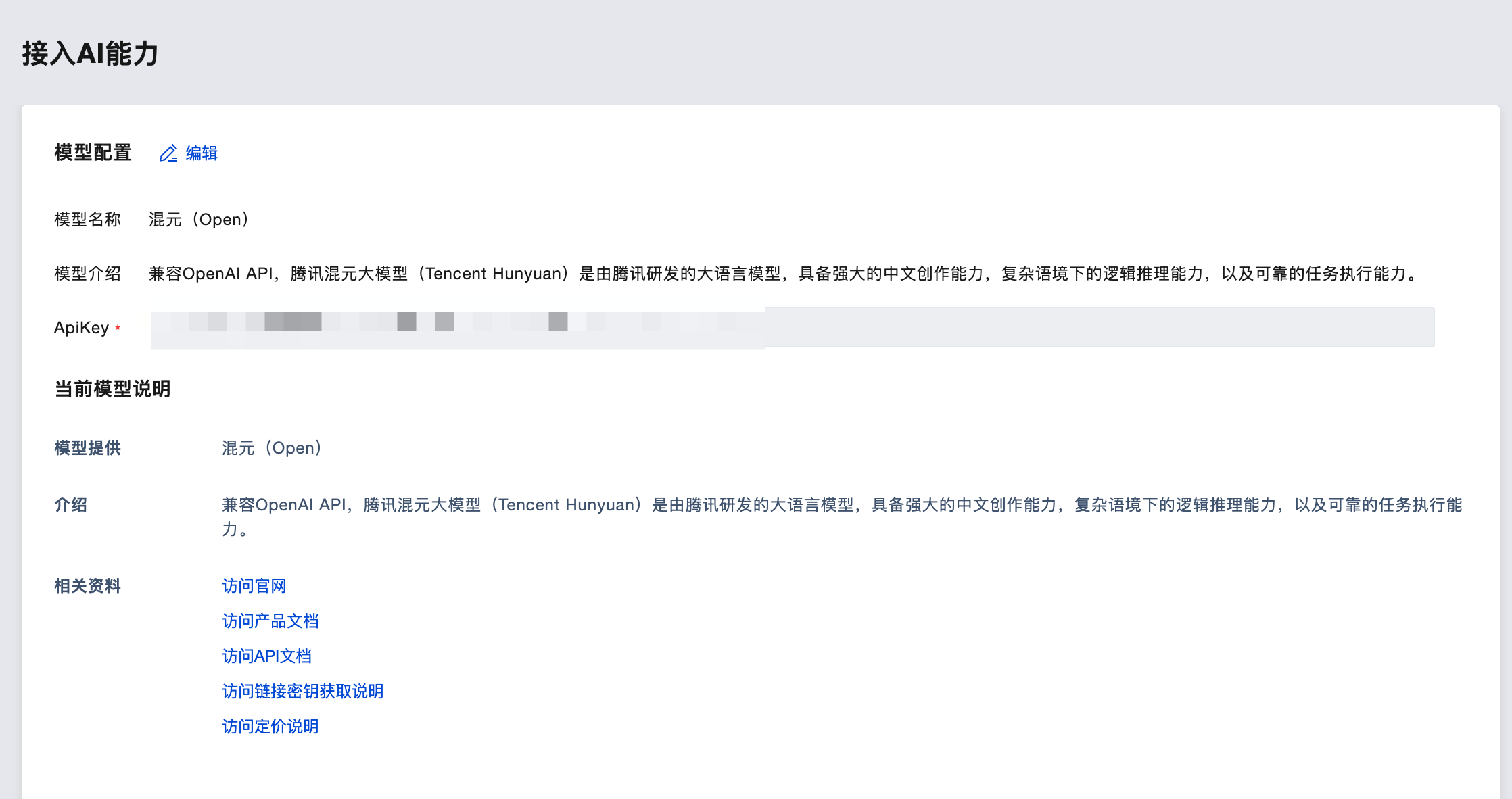
首先,进入云开发 AI+配置配置我们想用的大模型。这里我们选择配置混元(Open)。
搭建页面
接下来,我们进入到可视化开发页面。
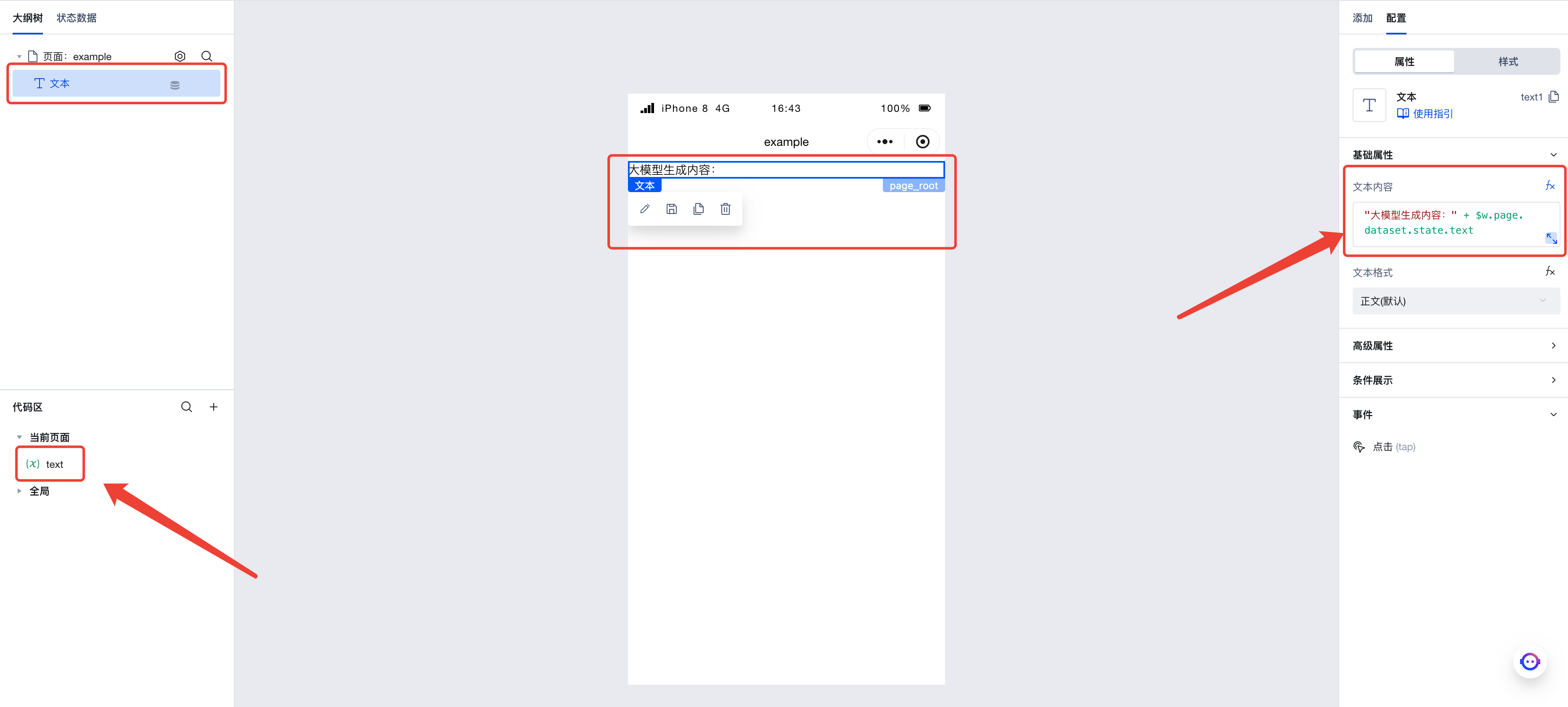
首先,我们在本页面中新建一个字符串变量 text,并新建一个文本组件,并将文本组件的内容设置为 "大模型生成内容:" + $w.page.dataset.state.text。我们会把大模型的输出结果保存到此变量中,从而可以在应用中显示出大模型的输出结果。
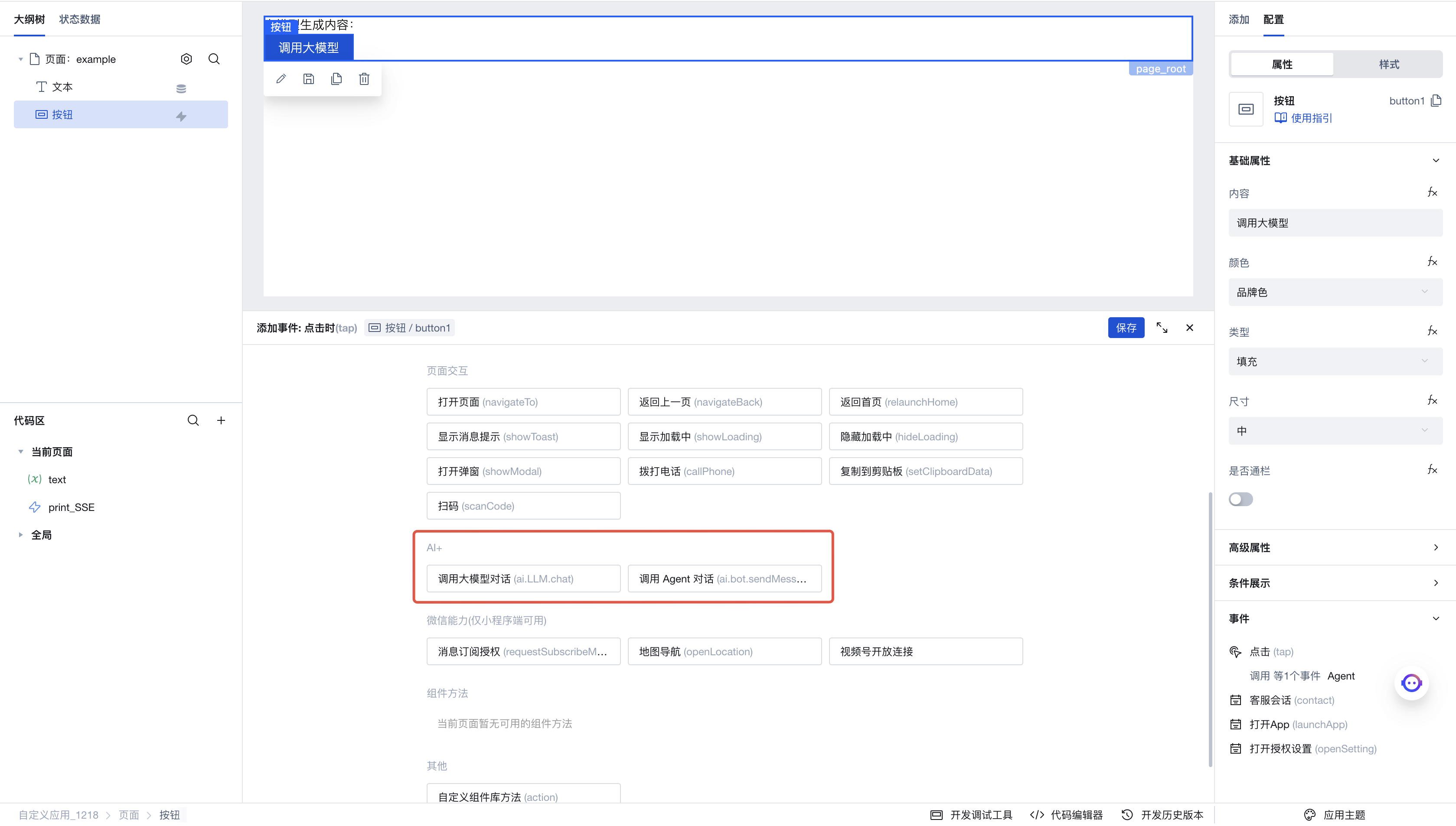
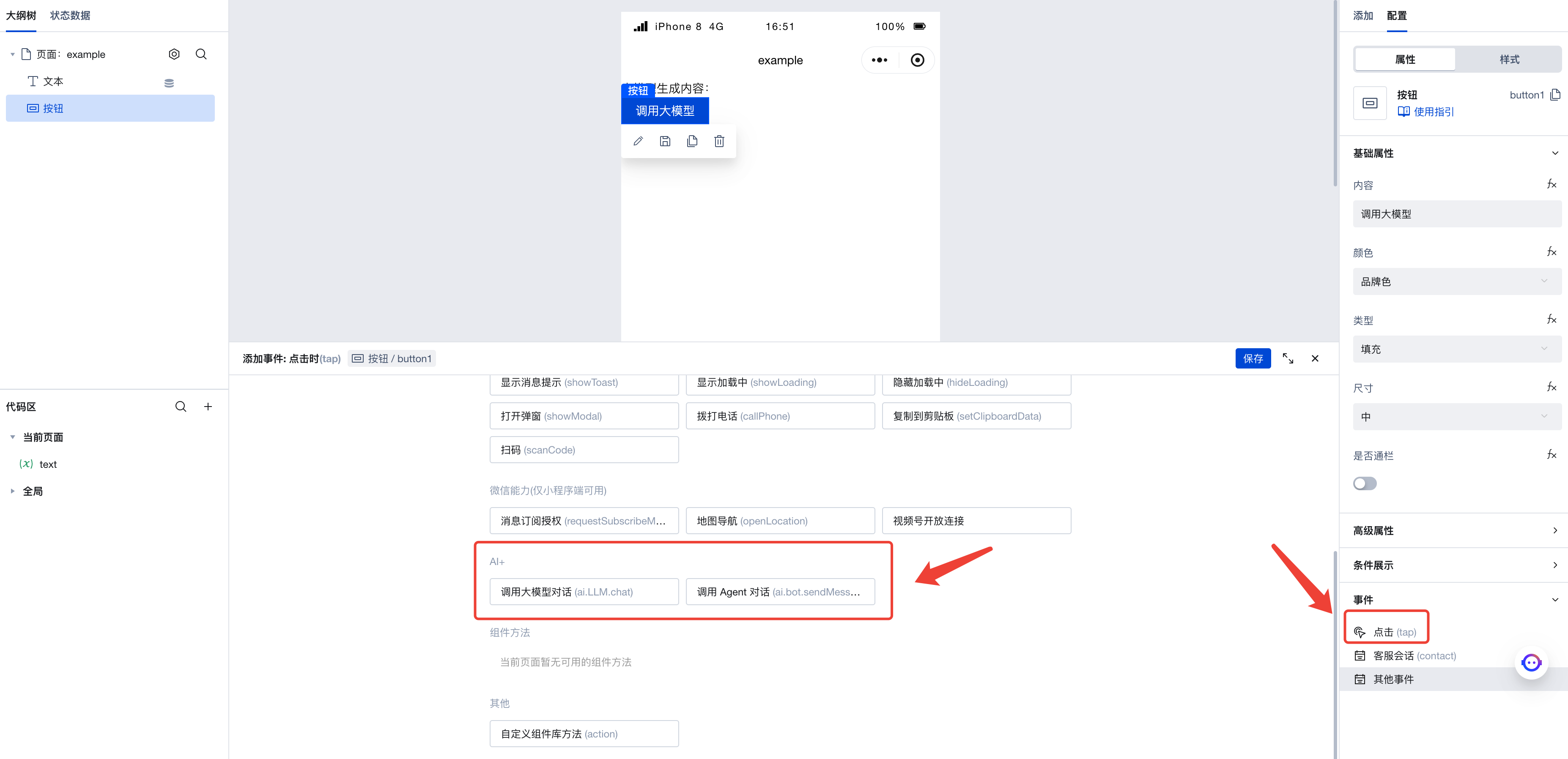
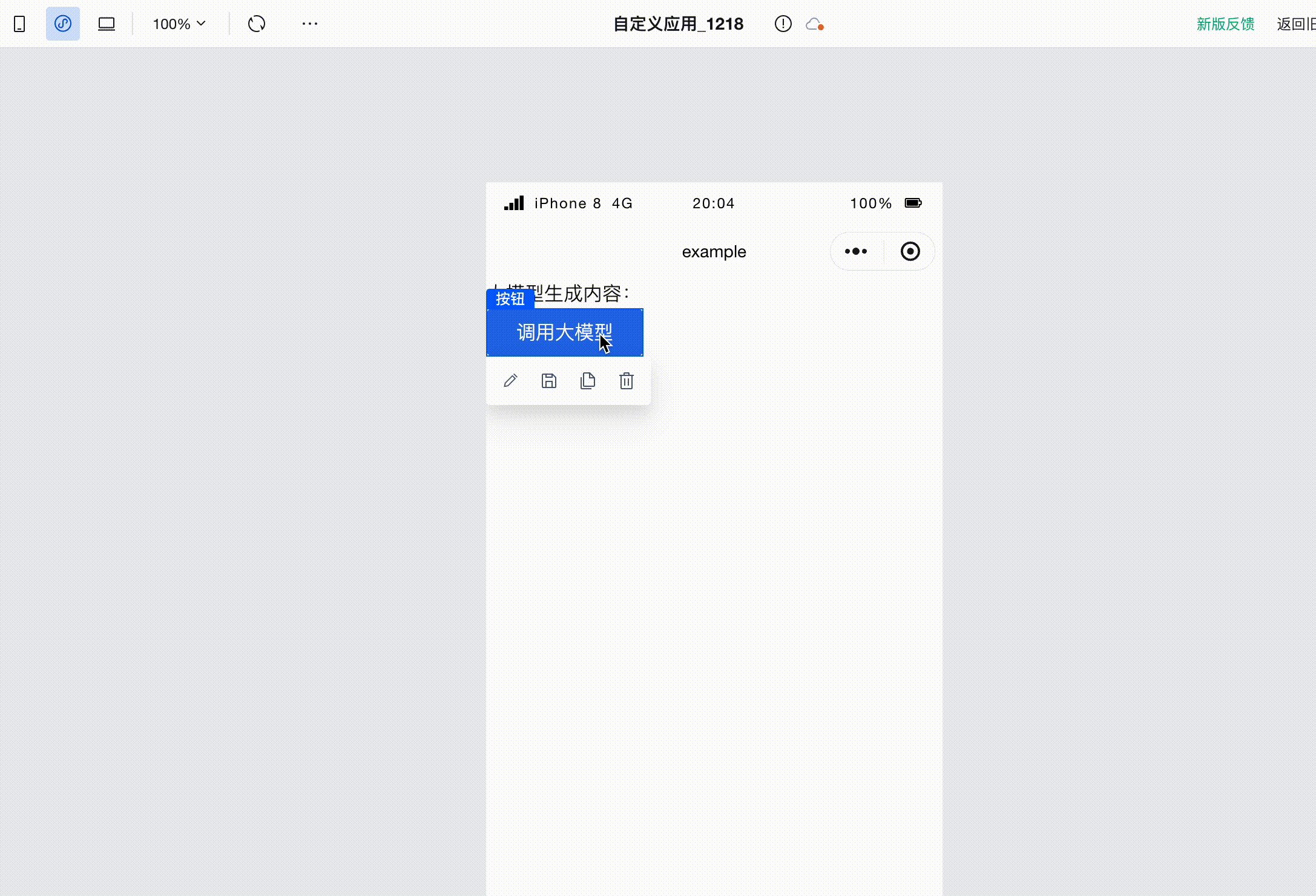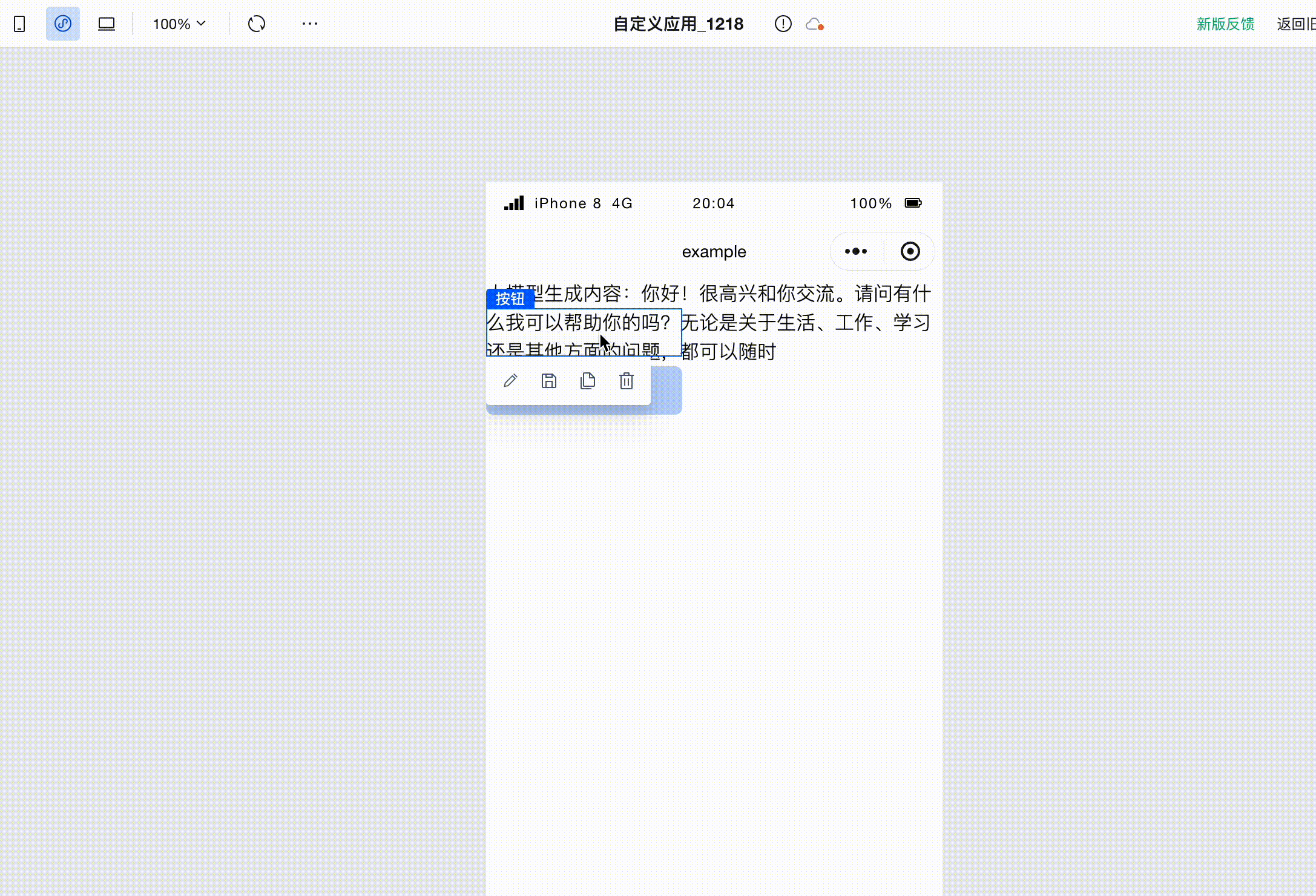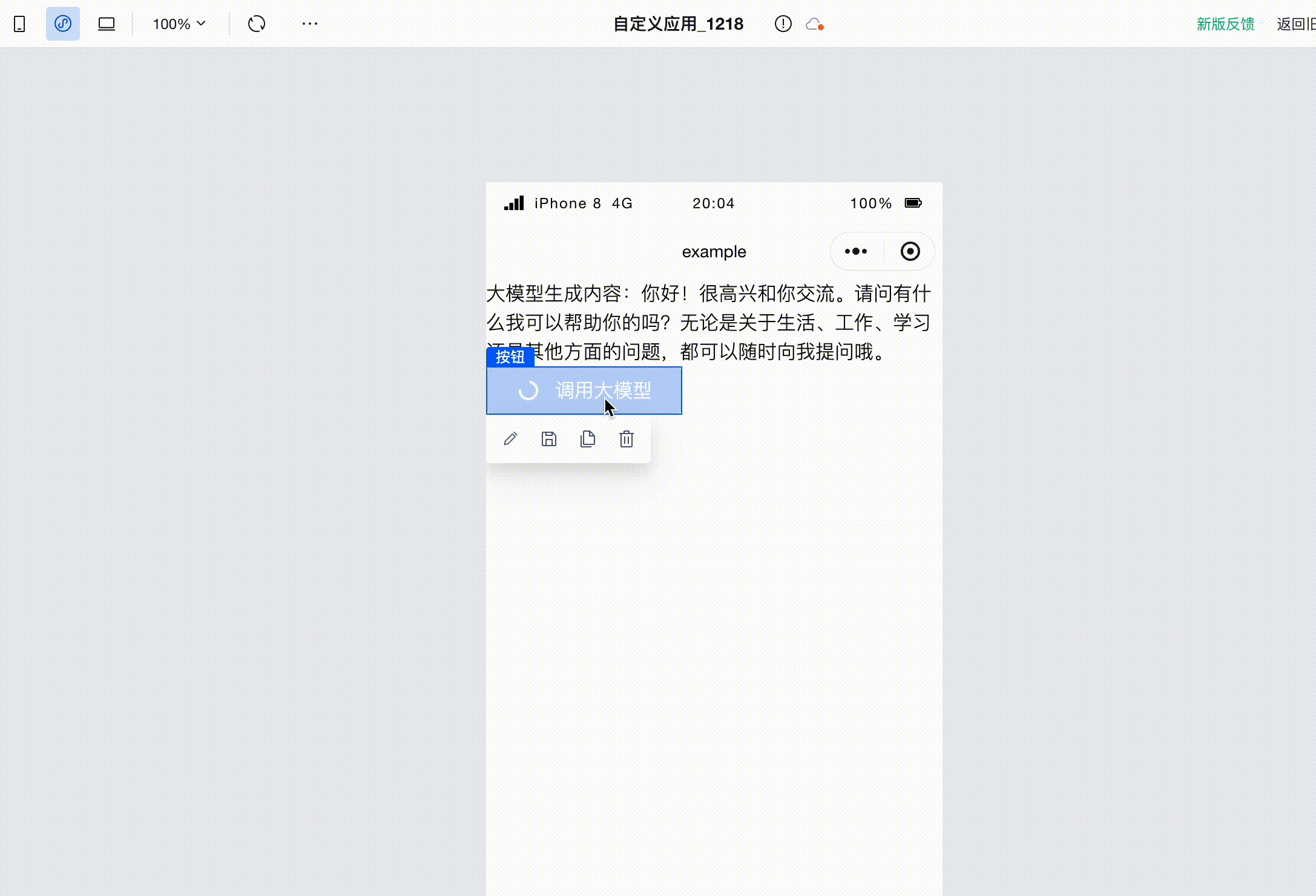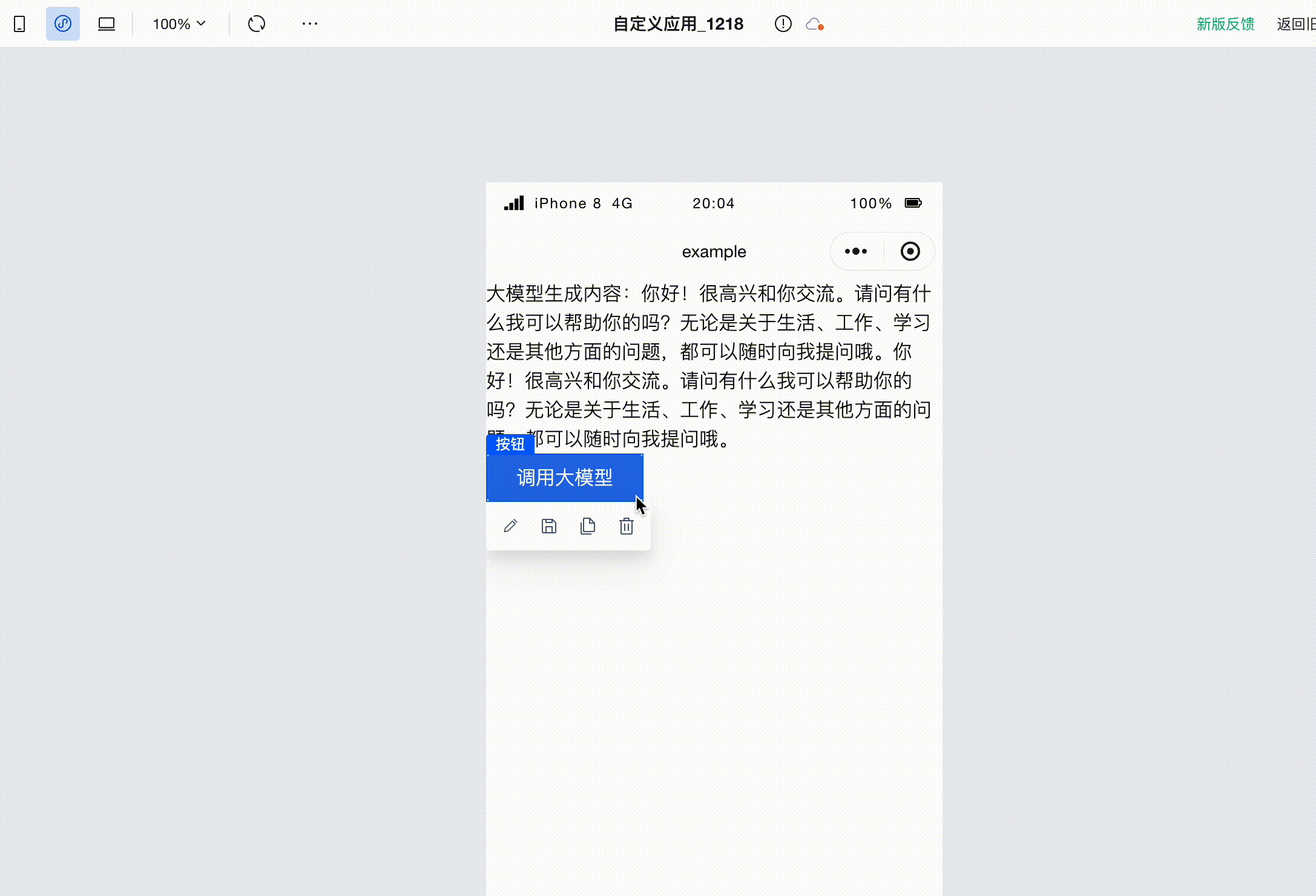
接着,在页面中添加一个按钮,点击右侧菜单中的点击事件,即可唤出执行动作面板。在此选择当此按钮被点击时会触发的执行动作。
点击「调用大模型对话」,进入执行动作的参数配置面板,这里是我们配置的参数:
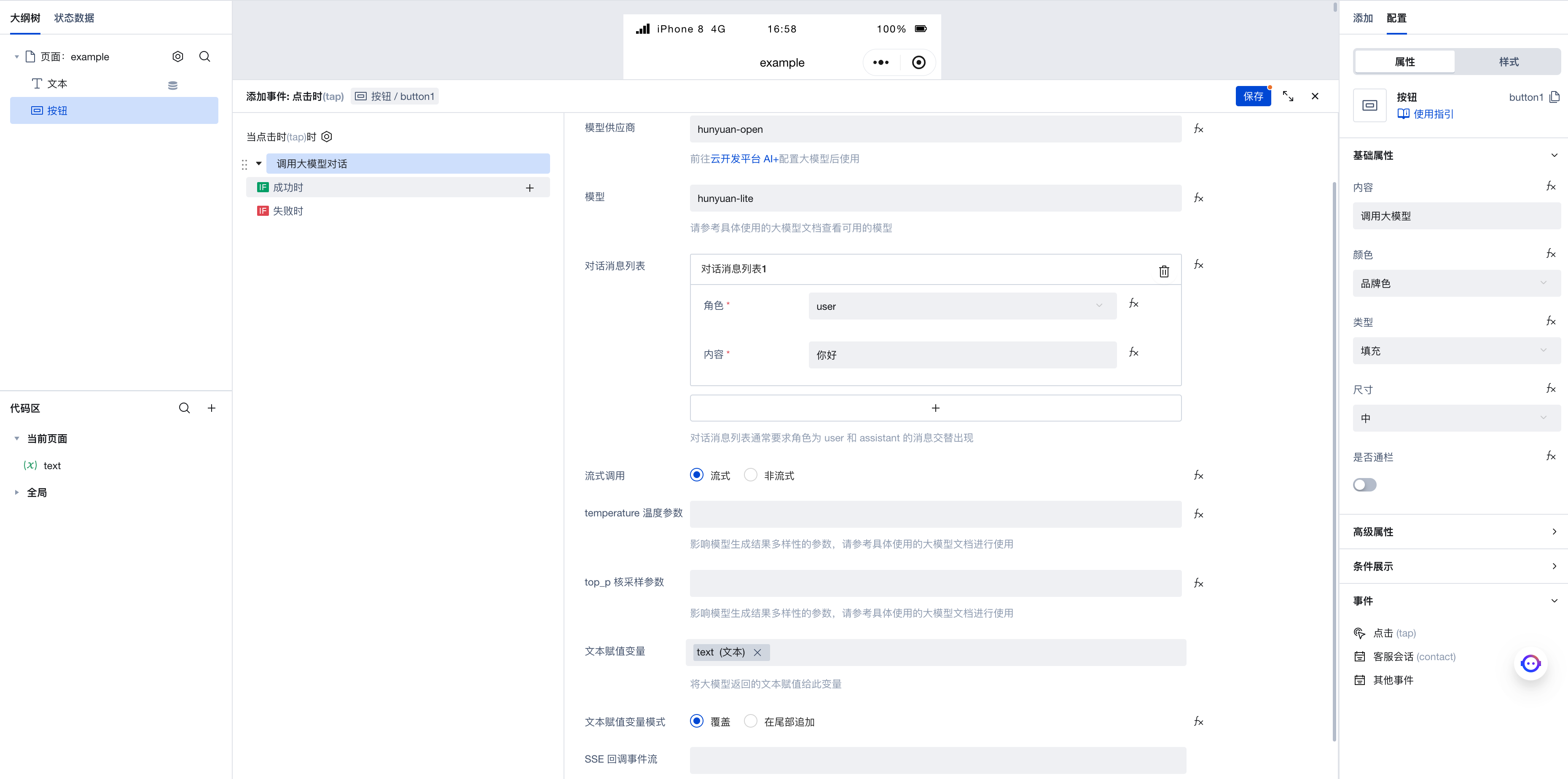
- 模型供应商:设置为
cloudbase,对应我们刚刚配置的大模型 - 模型:设置为
deepseek-v4-flash - 对话消息列表:添加一条消息,角色为
user,意为这是我们对大模型发送的消息 - 流式调用:选中「流式」,开��启流式调用。后续调用大模型时,每当大模型有新的内容生成,我们就能够接收到响应。不需要等待整个文本处理完毕,可以边产生文本边得到结果。当然有需要的话也可关闭流式调用,这样我们能够一次性得到完整的大模型生成结果
- temperature 温度参数:这个参数用来控制大模型生成文本的多样性,建议参考具体使用的大模型文档详细了解后再按需使用,这里我们就先不设置此参数了
- top_p 核采样参数:同 temperature 温度参数,我们此处先不设置
- 文本赋值变量:此处我们选中刚刚新建的
text变量,当我们获取到大模型的生成文本时,会将文本保存到此变量中。此前我们新建了绑定该变量的文本组件,因此预期效果是,当大模型生成文本时,会自动更新文本组件的内容 - SSE 回调事件流:当接收到 SSE 流式调用时,会触发此事件流。我们先不配置这个参数,后文将会详细介绍下这个参数的用法
配置完成后,点击保存。在页面中点击按钮,即可调用大模型,并看到大模型生成的文本在页面上被打印出来了。

进阶:配置 SSE 回调事件流
还记得上一小节我们没有配置的「SSE 回调事件流」参数吗?在这一小节我们将详细介绍下这个参数该如何使用。
大模型和 Agent 的流式调用都是基于 SSE 实现的。当大模型生成了新的内容时,就会返回一个 SSE 事件。在 SSE 事件中,包含着这次生成的详细信息,包括生成内容、时间、ID 等等。有进阶需求的开发者们或许希望充分解析 SSE 事件中传递的信息,此时就能够配置「SSE 回调事件流」参数实现。
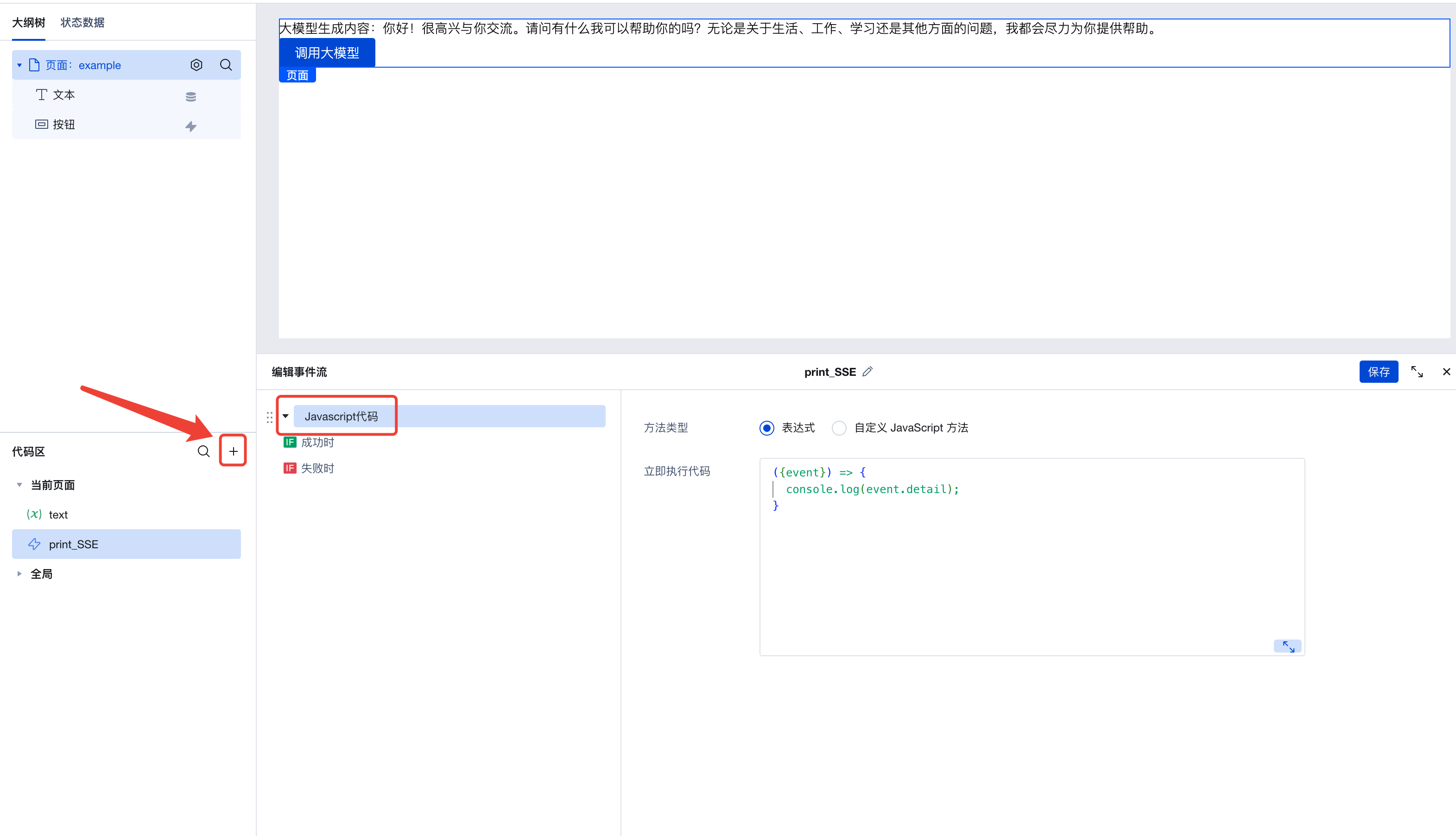
在左侧代码区新建一个 print_SSE 的事件流,设置为 Javascript 代码事件,并填入这段代码:
// 这段代码会打印出接收到的 SSE 事件。
({event}) => {
console.log(event.detail);
}
配置好后,再次打开「调用大模型对话」的参数配置面板,在「SSE 回调事件流」参数中,添加刚刚新建的 print_SSE 事件流。
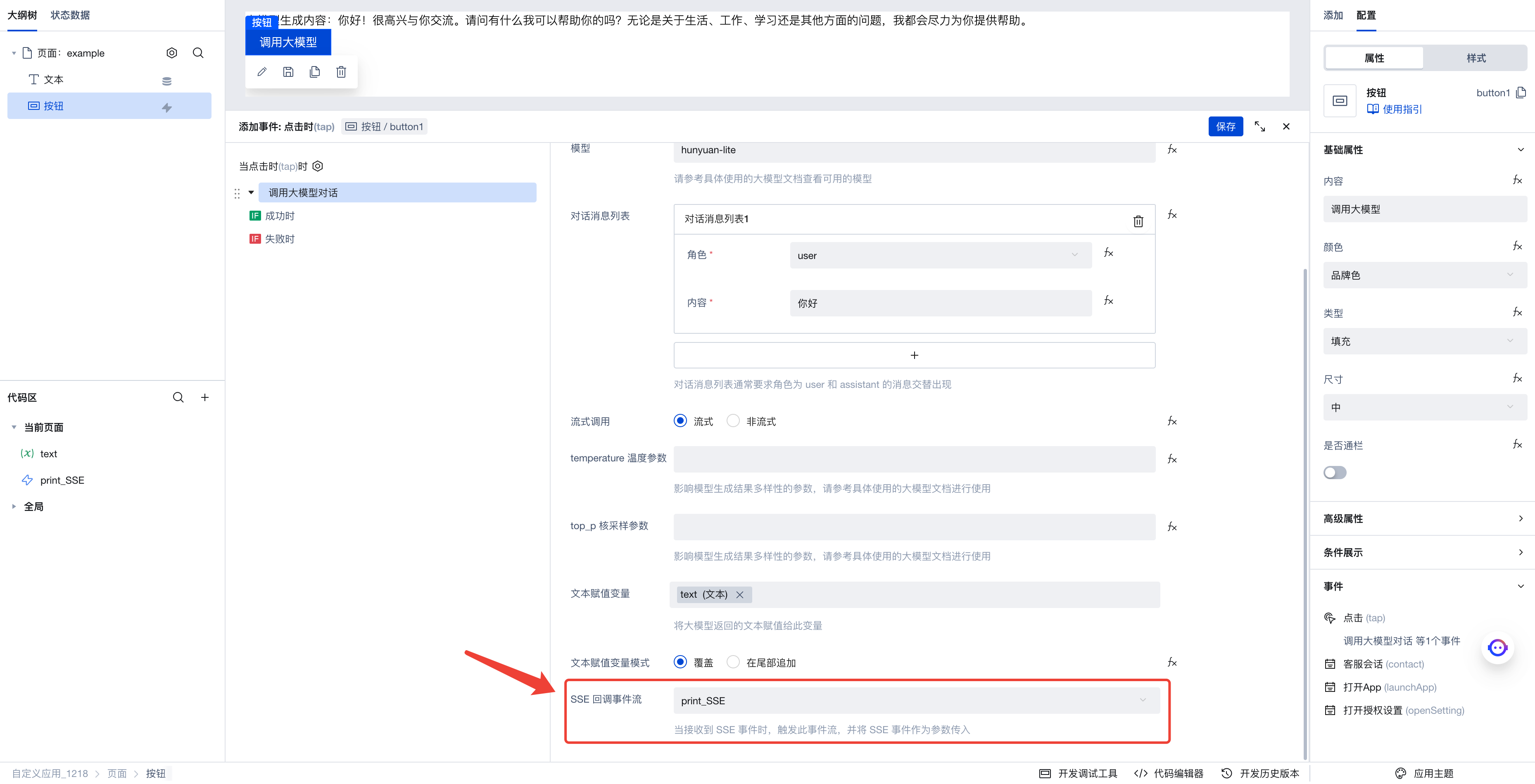
点击保存,即可开始运行了。打开浏览器的开发者控制台,再次点击按钮,即可调用大模型,生成的文本显示在应用界面中,同时控制台也打印出了接收到的一系列 SSE 事件。

调用 Agent 对话
本小节我们将演示如何使用「调用 Agent 对话」执行动作。
配置 Agent
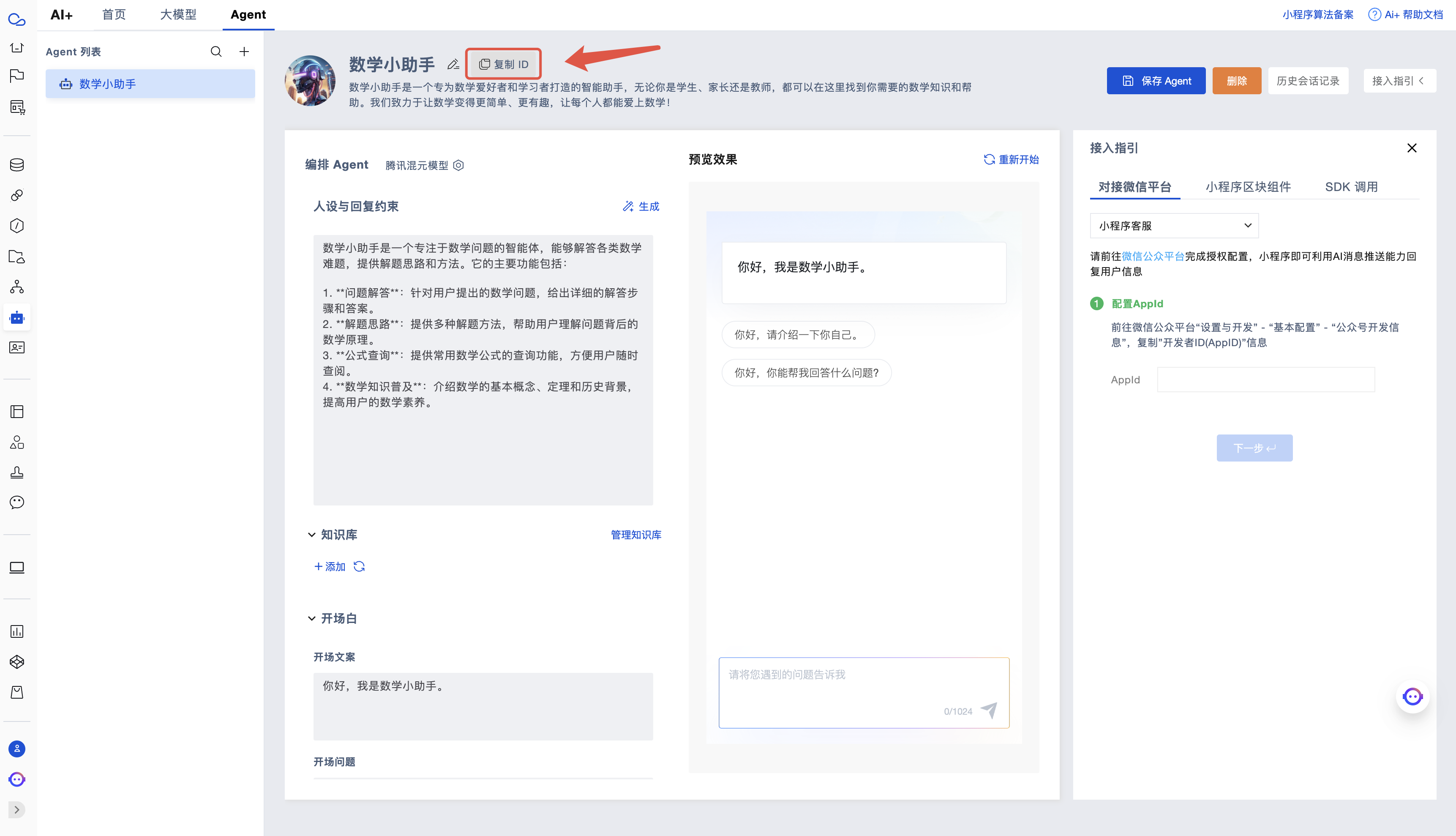
首先,进入云开发 AI+配置配置我们想用的 Agent,点击复制 ID 按钮记录下来该 Agent 的 ID。
搭建页面
接下来,我们进入到可视化开发页面。
首先,我们在本页面中新建一个字符串变量 text,并新建一个文本组件,并将文本组件的内容设置为 "Agent 生成内容:" + $w.page.dataset.state.text。我们会把 Agent 的输出结果保存到此变量中,从而可以在应用中显示出 Agent 的输出结果。
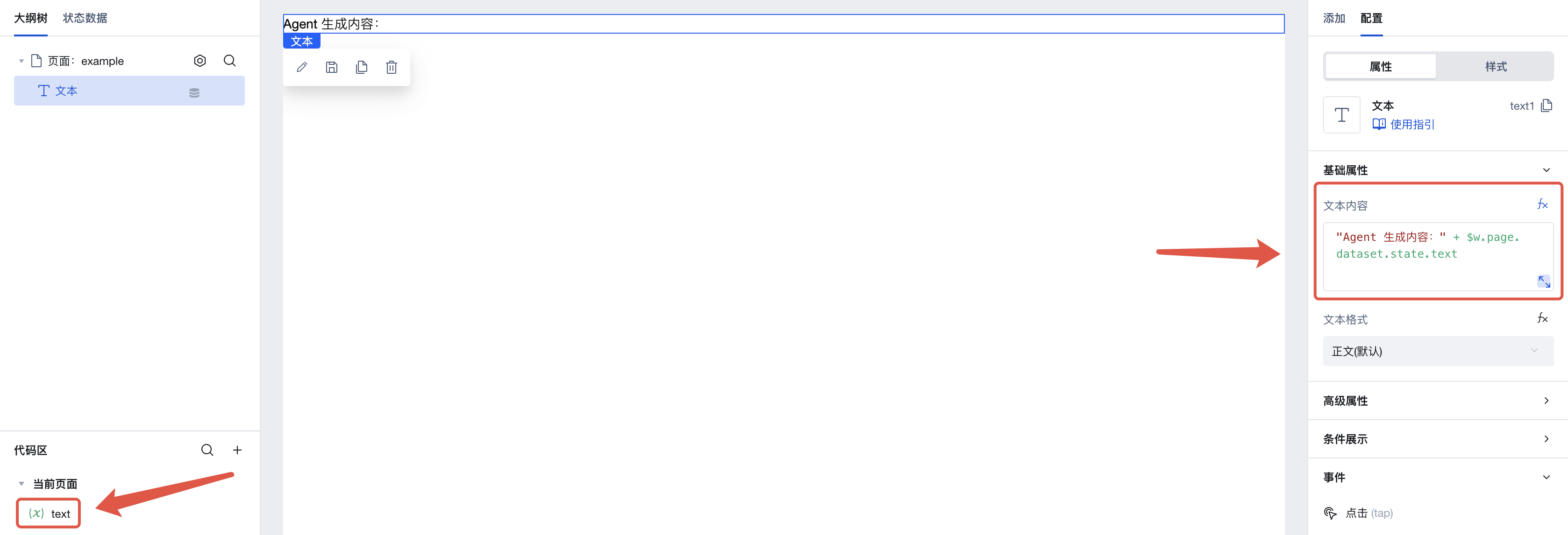
接着,在页面中添加一个按钮,点击右侧菜单中的点击事件,即可唤出执行动作面板。在此选择当此按钮被点击时会触发的执行动作。
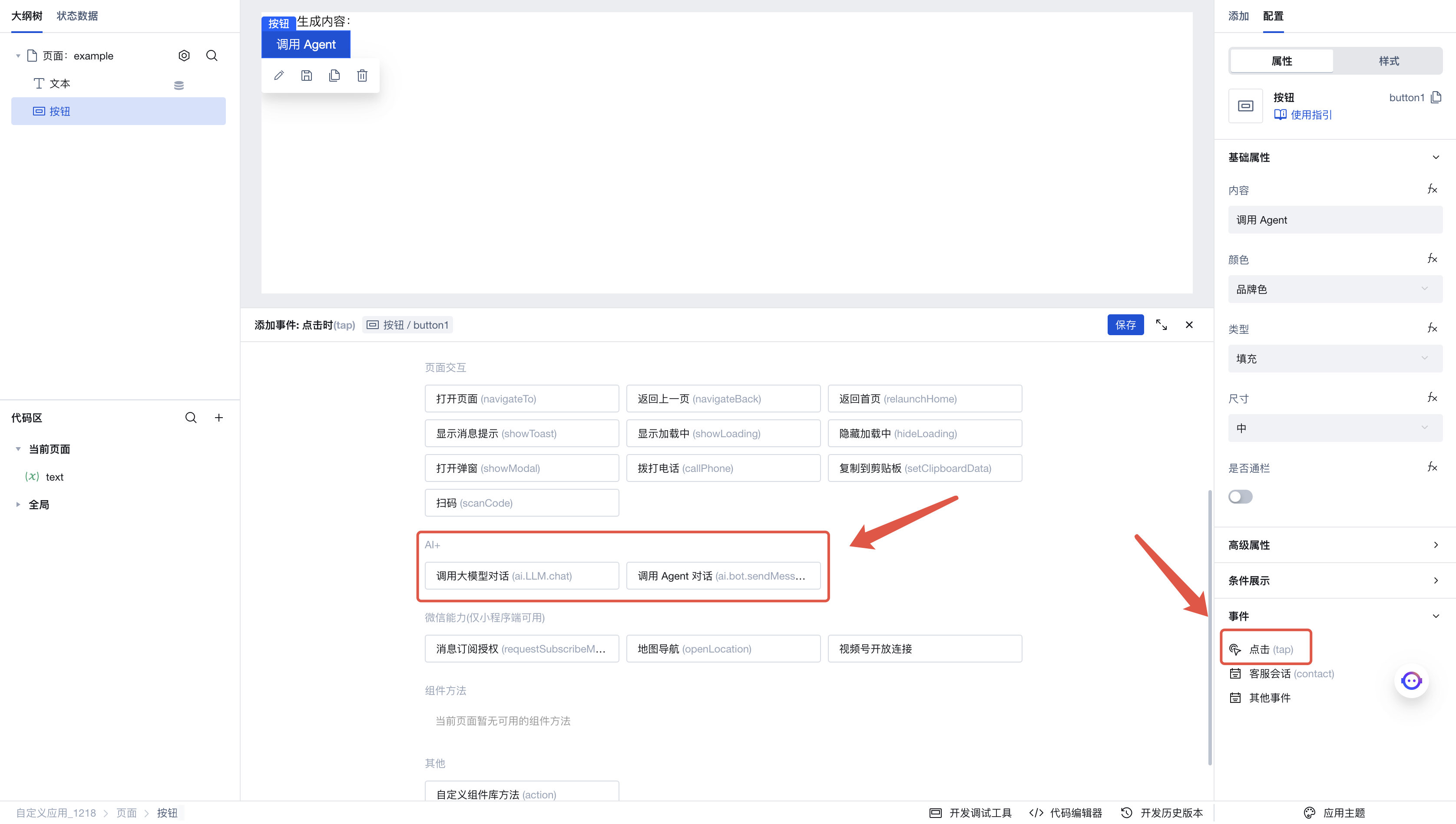
点击「调用 Agent 对话」,进入执行动作的参数配置面板,这里是我们配置的参数:
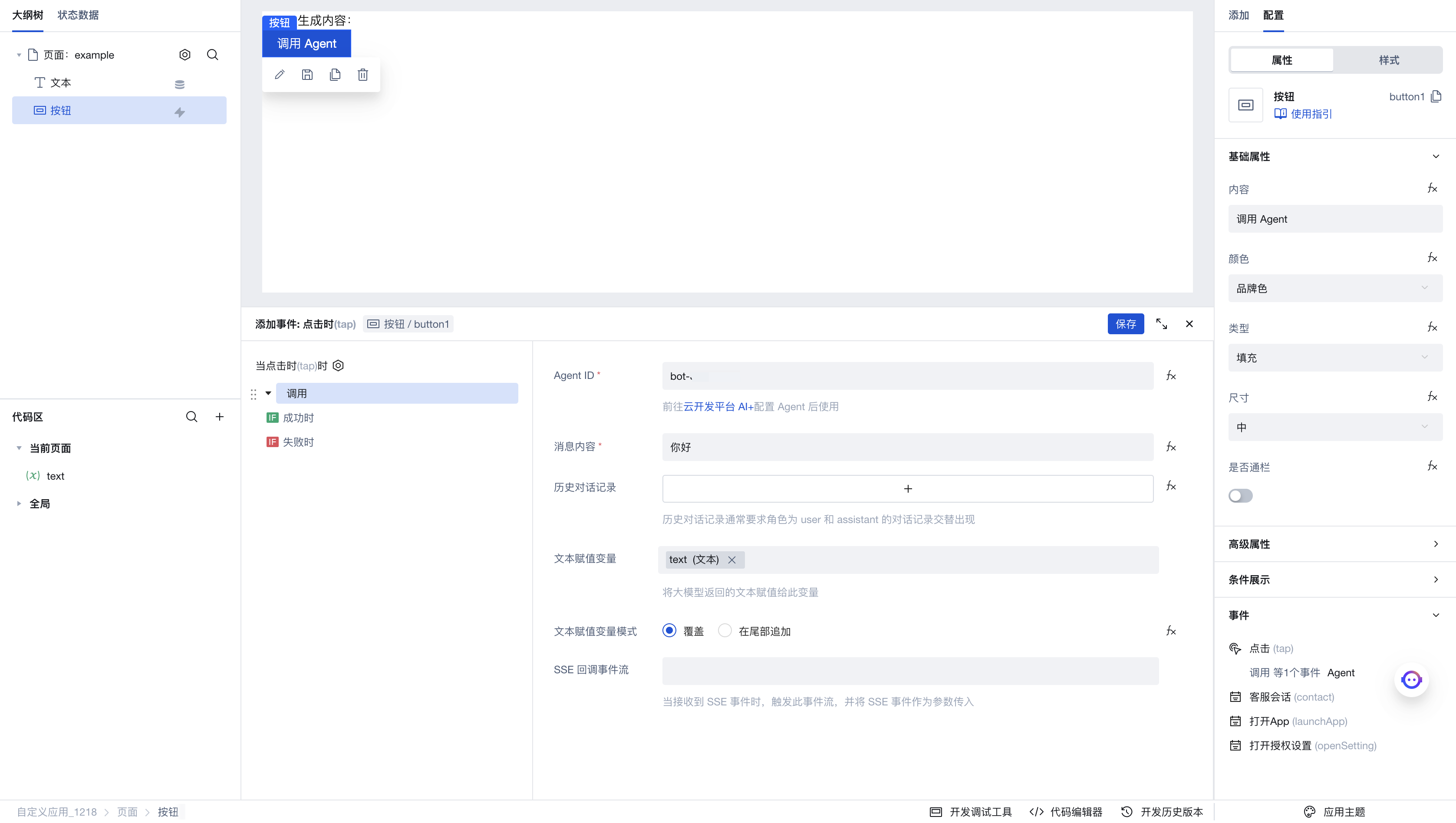
- Agent ID:填入刚刚在 AI+ 页面中配置好的 Agent ID
- 消息内容:填入要发送给 Agent 的对话内容
- 历史对话记录:如果有添加上下文的需求,可以在此填入你和 Agent 的历史对话列表
- 文本赋值变量:此处我们选中刚刚新建的
text变量,当我们获取到 Agent 的生成文本时,会将文本保存到此变量中。此前我们新建了绑定该变量的文本组件,因此预期效果是,当 Agent 生成文本时,会自动更新文本组件的内容 - SSE 回调事件流:当接收到 SSE ��流式调用时,会触发此事件流。可以参考调用大模型对话中的使用示例进行使用
配置完成后,点击保存。在页面中点击按钮,即可调用 Agent,并看到 Agent 生成的文本在页面上被打印出来了。

最佳实践
在应用中体现「加载中」的状态
调用大模型、Agent 对话时,需要耗费一定时间才能看到响应。为了让用户感知到应用正在等待调用完成、防止多次调用造成赋值混乱等现象,我们可以在应用中体现出「加载中」的状态。
首先,按照调用大模型对话使用示例,搭建出一个能够调用大模型的应用。预期中,此时页面上会有:
- 一个文本组件
- 一个按钮组件
- 一个
text文本变量
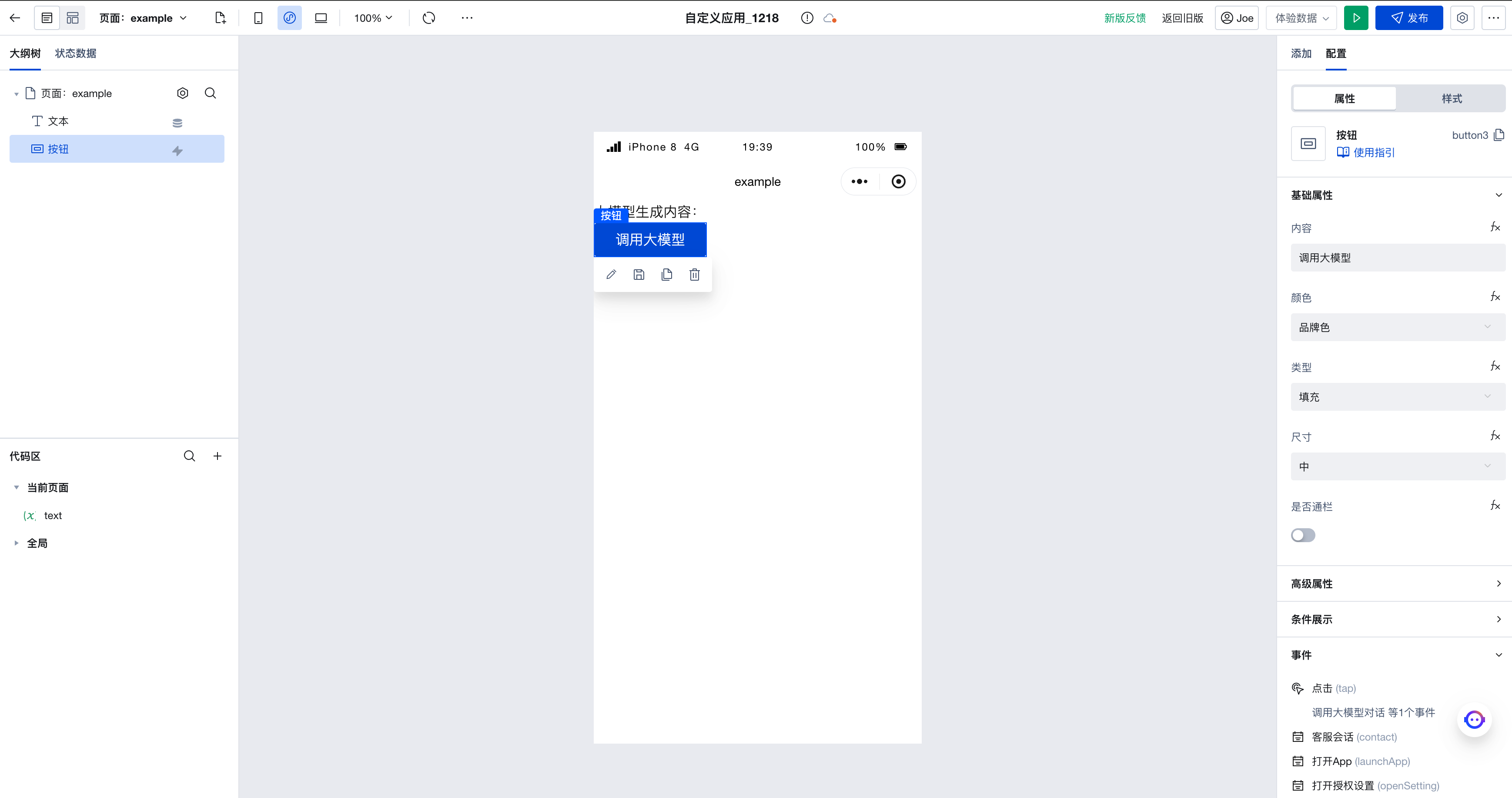
其中,按钮组件绑定了调用大模型的动作;文本组件的值被绑定为 "大模型生成内容:" + $w.page.dataset.state.text。当点击按钮时,会调用大模型,页面中出现大模型生成内容。
接下来,新建一个 loading 变�量,类型为布尔值,默认值设置为 false,这个值会用来表示我们的「加载中」状态。
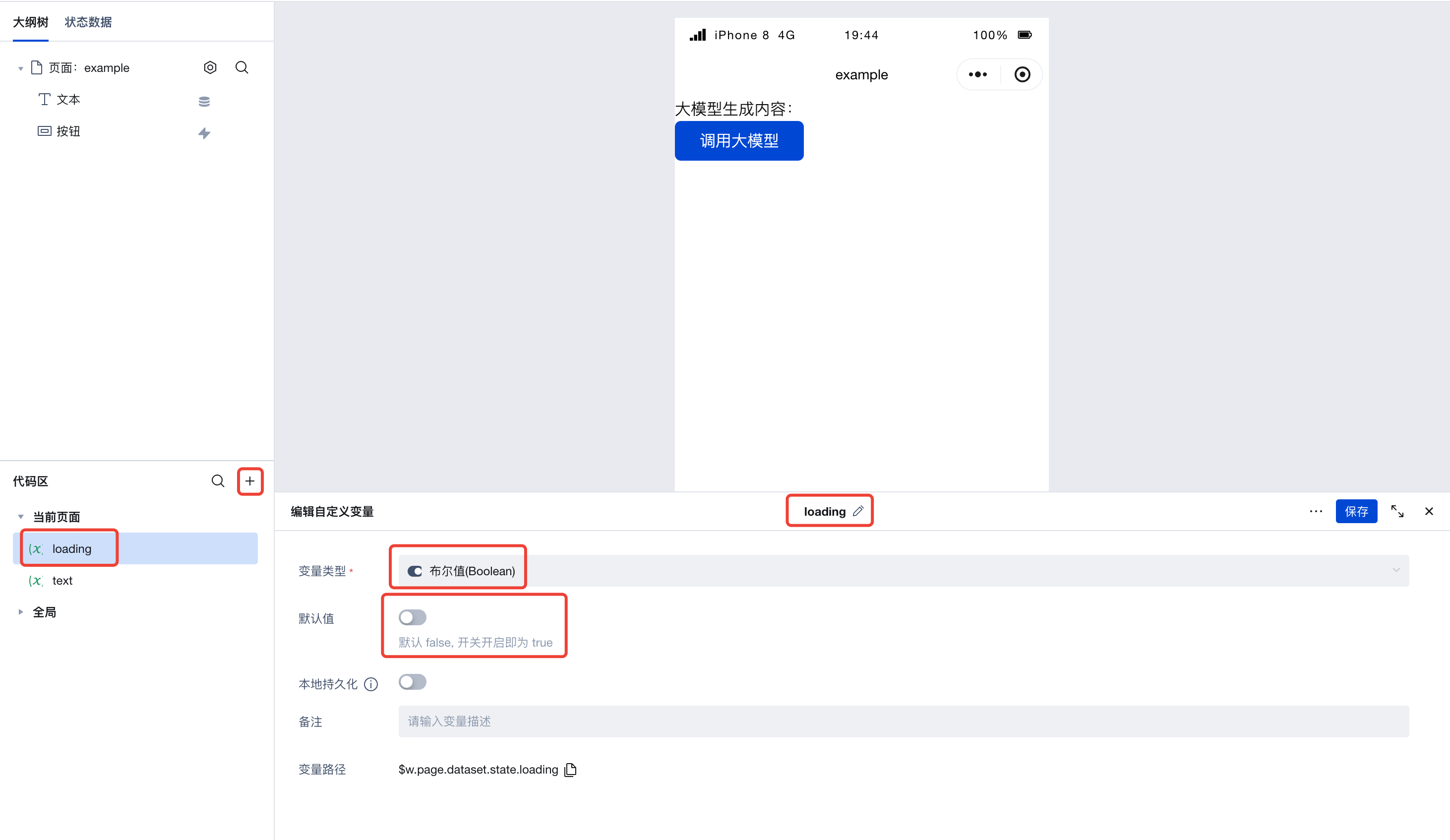
随后,我们配置下按钮组件,在右方的高级属性栏下,可以找到「加载中」和「禁用」的属性,点击切换为表达式,绑定上我们刚刚新建的 loading 变量。
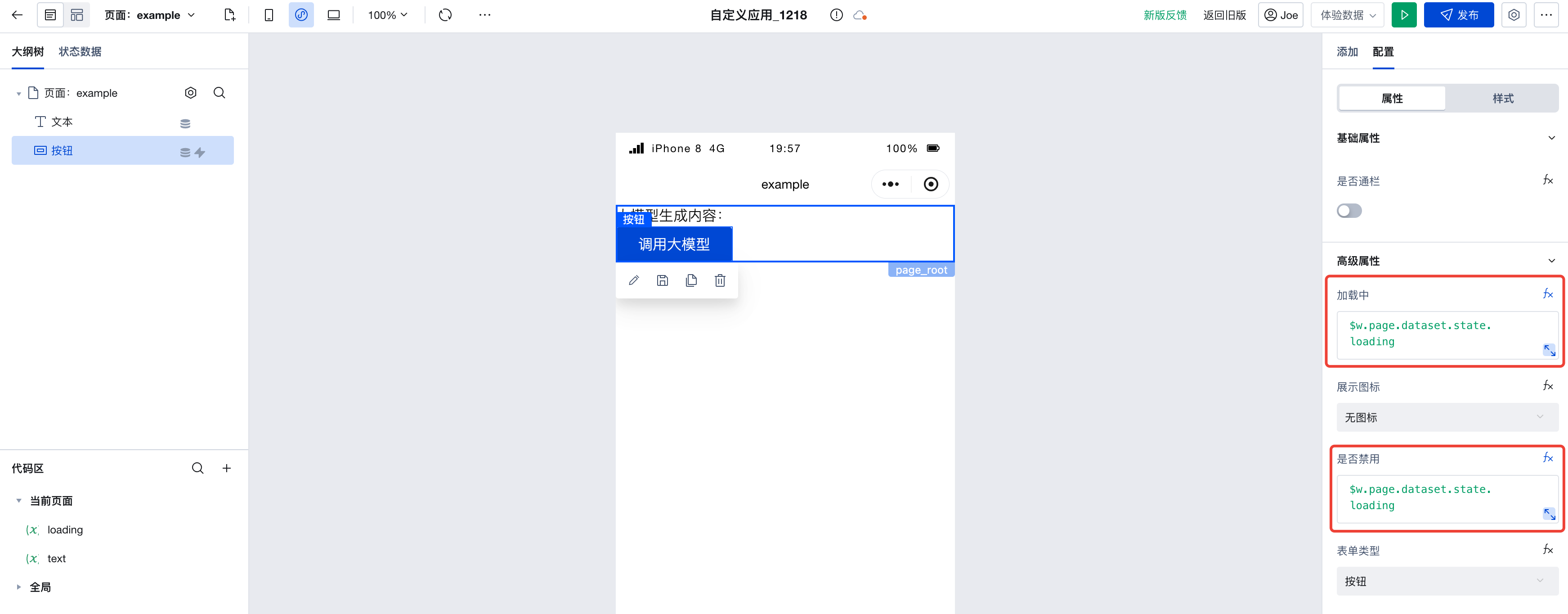
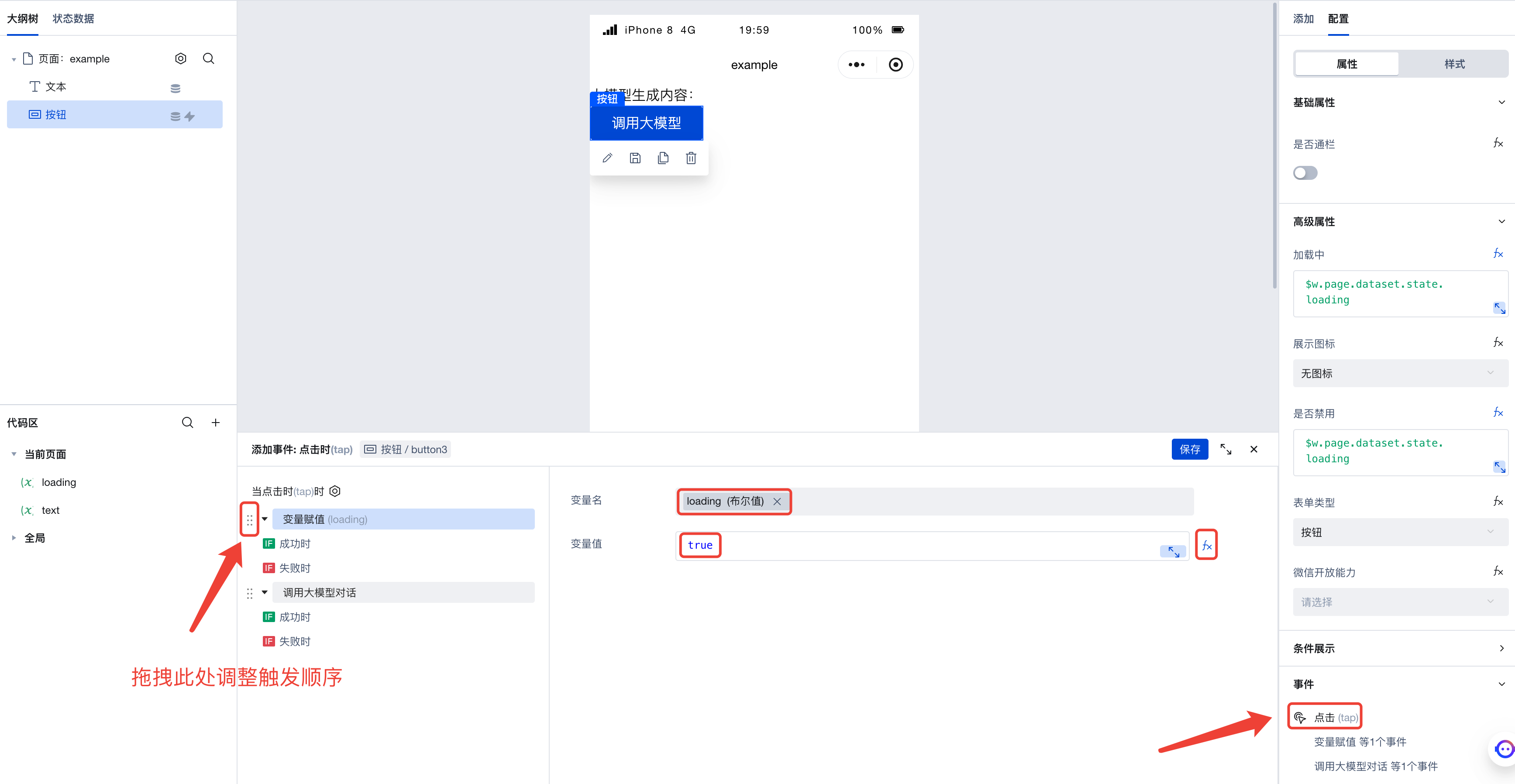
最后,只要分别在调用大模型前后给 loading 变量赋上不同的值就可以了。
先在调用大模型之前给 loading 变量赋上 true 的值。由于调用大模型是在点击后触发的动作,因此只要在点击事件上加上赋值变量的动作即可:
接着,在调用大模型成功时,再加上赋值变量的动作即可。在这里,我们给 loading 变量赋上 false 的值:
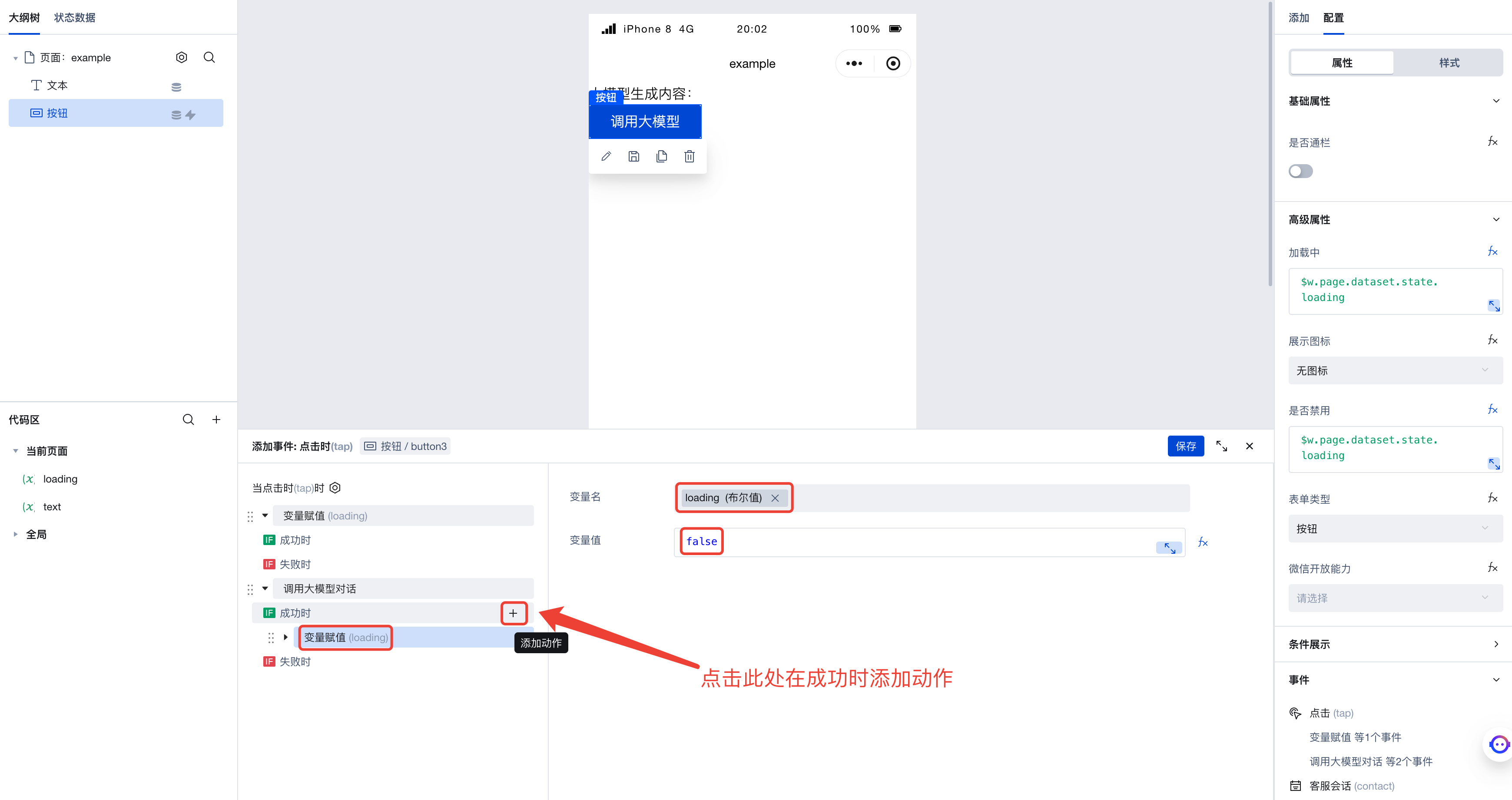
运行代码,即可看到在调用大模型时,按钮状态为加载中,且不可用。这样一来既让用户感知到了请求状态,也防止用户多次点击重复触发了。在大模型调用结束后,按钮状态也随之恢复正常,可以再次点击了。
调用混元图生文能力
混元大模型具备图生文能力,在微搭「调用大模型」的执行动作中,也可以传入图片相关的参数,让大模型读取图片。
首先,按照调用大模型对话使用示例,搭建出一个能够调用大模型的应用。预期中,此时页面上会有:
- 一个文本组件
- 一个按钮组件
- 一个
text文本变量
其中,按钮组件绑定了调用大模型的动作;文本组件的值被绑定为 "大模型生成内容:" + $w.page.dataset.state.text。当点击按钮时,会调用大模型,页面中出现大模型生成内容。
接着,让我们修改下「调用大模型」动作的配置。这是我们修改前的动作配置:
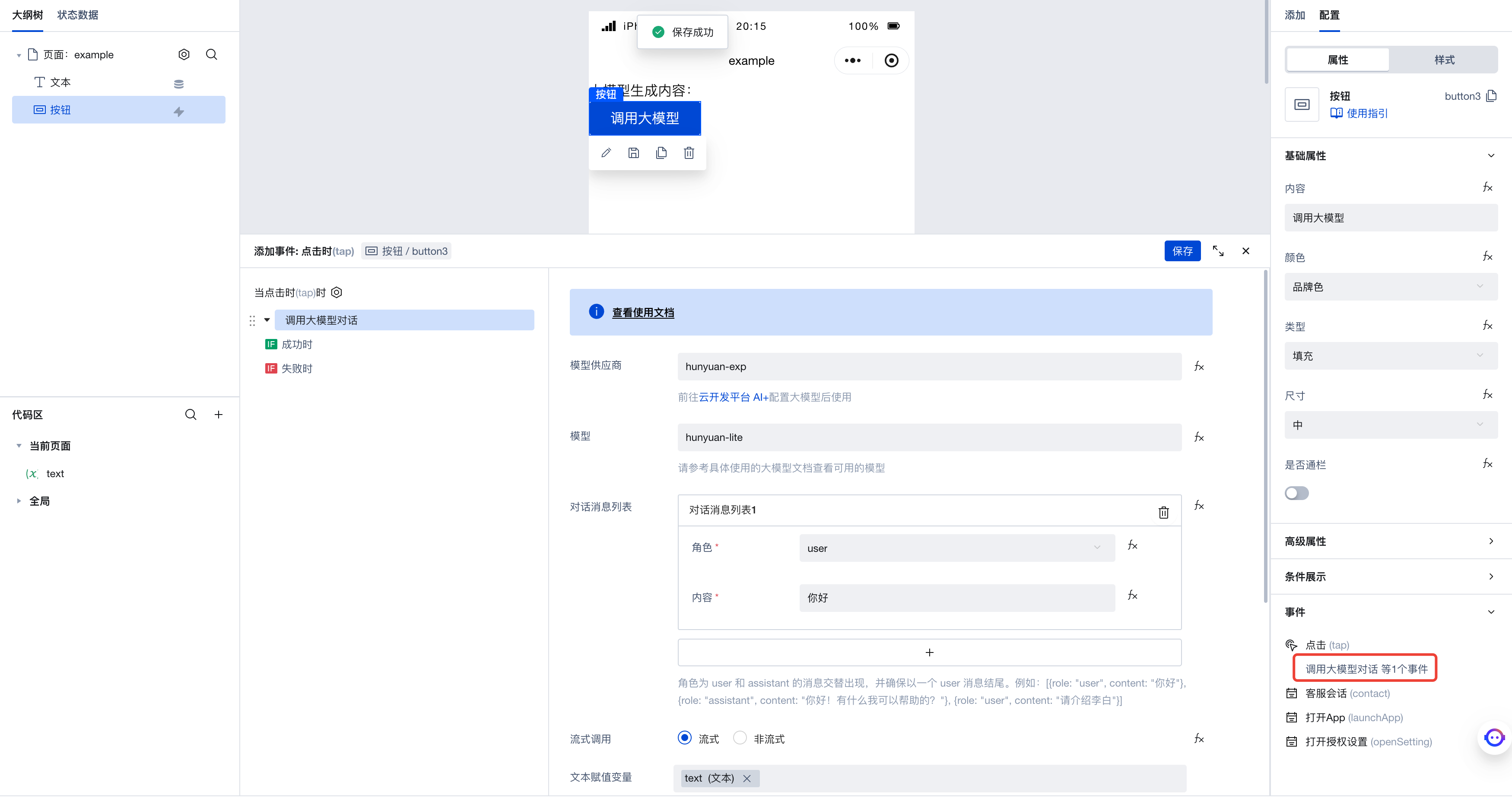
可以看到,表单中并没有地方输入图片内容。点击「对话消息列表」表单右边的 fx 图标,会看见对应的表单变成了代码表达式。这是因为微搭提供了可视化的表单替代代码表达式。用户在操作表单时,实际上会改变对应的代码表达式。此时我们为了利用大模型的图生文能力,需要在此处直接填写代码表达式。
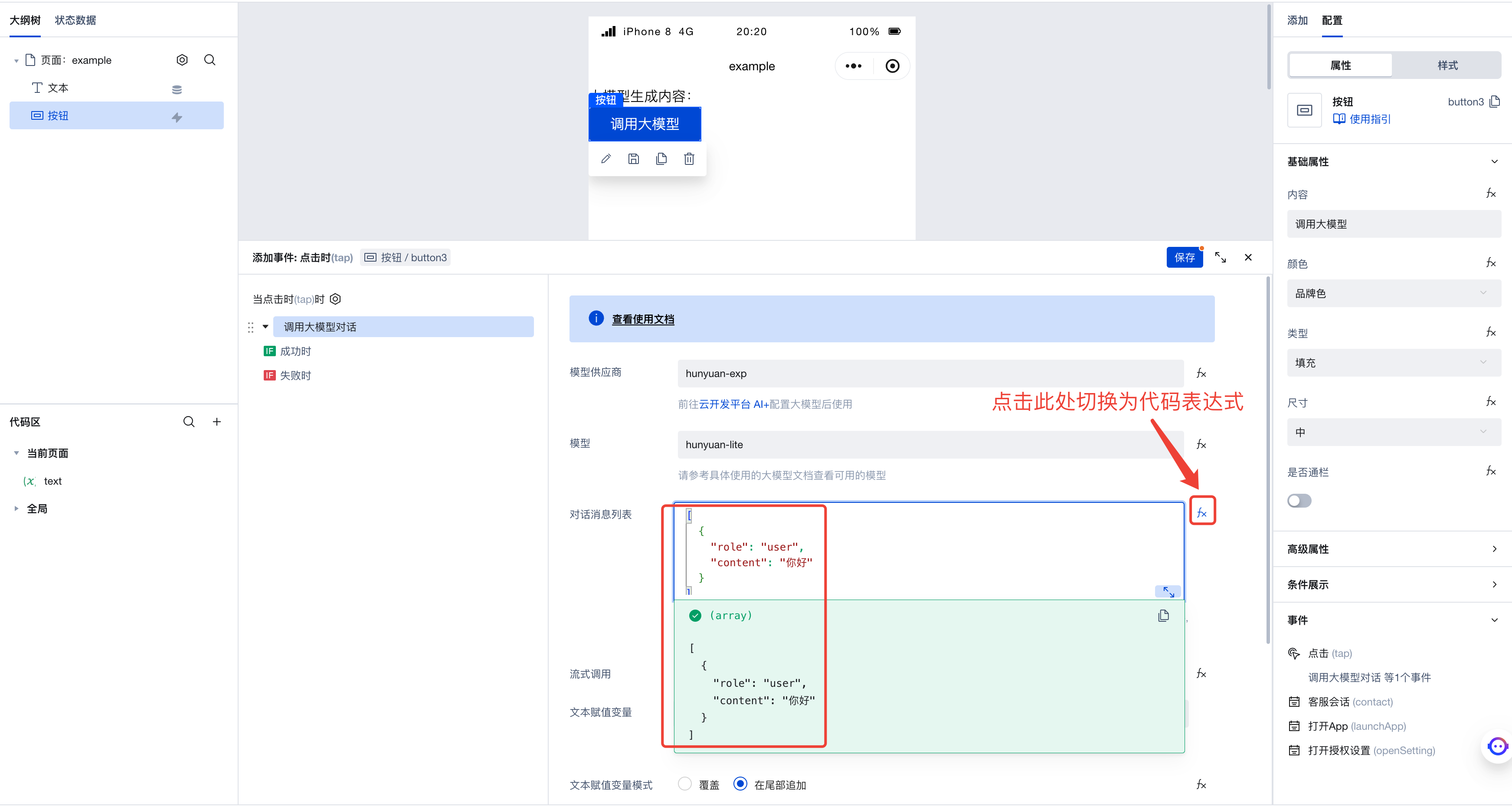
如图所示,我们这里的代码表达式为:
[
{
"role": "user",
"content": "你好"
}
]
这表示了发给大模型的对话消息列表,其中只有一条用户消息,内容为「你好」。
调用图生文时,代码格式要发生一些变化,上面的代码要写成:
[
{
"role": "user",
"content": [
{
"type": "text",
"text": "这个图片内容是什么?"
}
]
}
]
可以看到,本来写在 content 字段中的字符串「你好」,现在变成了一个数组,其中包含一个对象元素,它有两个字段:
type中填的是"text",表示这个元素是个文本类型的消息text中填的是"这个图片内容是什么?",就是这个消息的文本内容了
以上就是调用图生文时传入文本消息的方法。接下来我们再传入图片消息。我们在 content 字段的数组中追加一个表示图片消息的对象元素:
[
{
"role": "user",
"content": [
{
"type": "text",
"text": "这个图片内容是什么?"
},
{
"type": "image_url",
"image_url": {
"url": "https://cloudcache.tencent-cloud.com/qcloud/ui/portal-set/build/About/images/bg-product-series_87d.png"
}
}
]
}
]
这个对象元素也有两个字段:
type中填的是"image_url",表示这个元素是个图片的链接image_url中填的是一个带url字段的对象,就是这个消息对应的图片链接了
至此,大功告成,按照这样的格式就可以传入图片,调用大模型的图生文能力了。
最后,只需要选择具有图生文能力的模型即可,这里我们选择 hunyuan-vision。
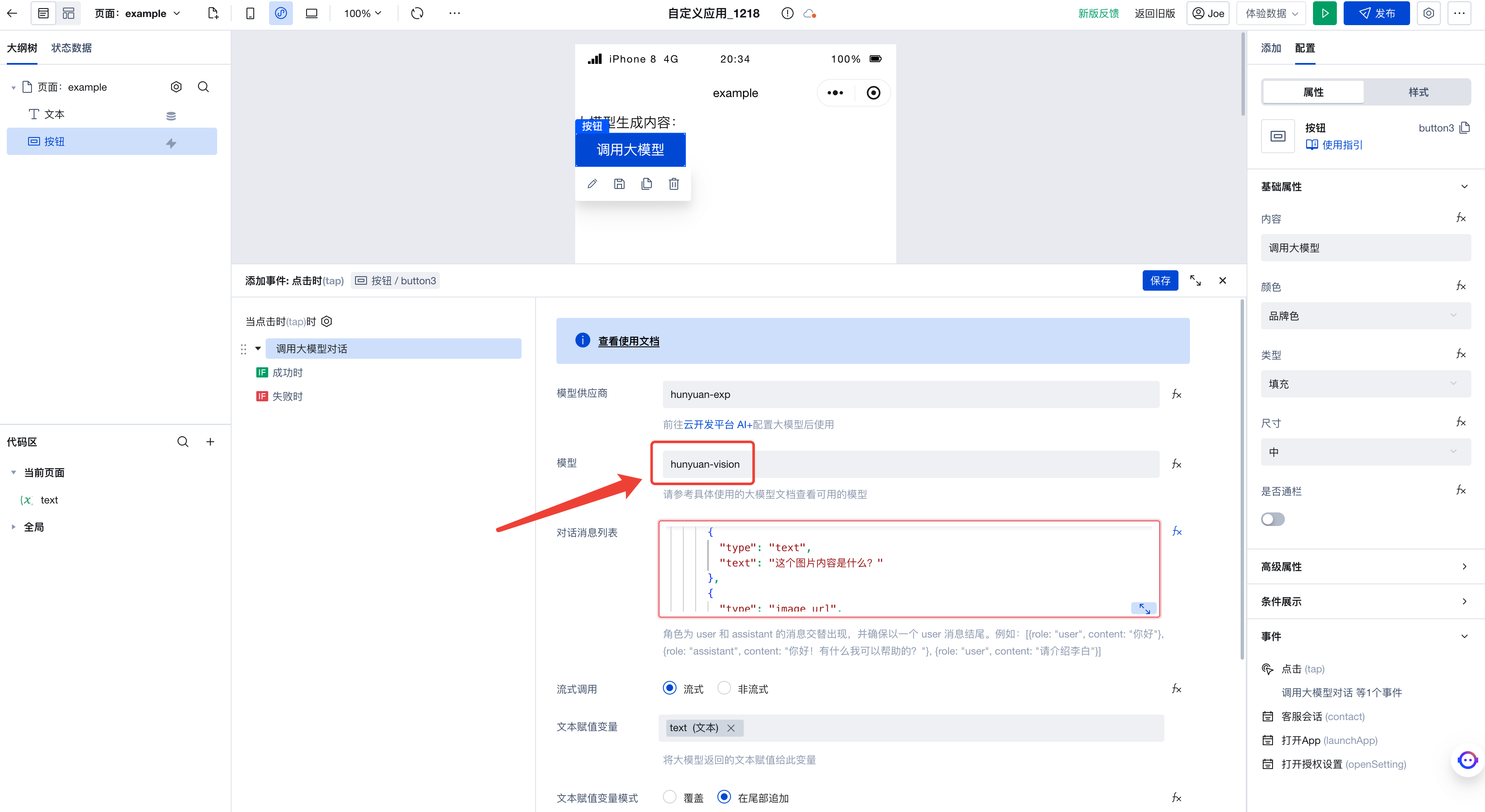
运行下代码,即可看到大模型对我们传入图片的解读了!