字段说明
数据模型字段为数据源的表结构基础,可以理解为 Excel 表格的表头(列),而数据可以理解为 Excel 表格的行。
字段类型
开发者可自定义数据模型字段,自定义字段支持类型如下:
| 数据类型 | 格式 | DB字段类型 | 使用说明 | 传参示例 |
|---|---|---|---|---|
| 文本 | 单行文本 | string | 最长可存储4000字节,如需存储更长内容,建议使用富文本类型 | "this is a string" |
| 多行文本 | string | 最长可存储4000字节,如需存储更长内容,建议使用富文本类型 | "this is a long-text" | |
| 布尔值 | - | boolean | true 或 false | true |
| 数字 | - | number | 数字 | 123456.78 |
| 数组 | 数组 | array | 根据数组的元素类型进行校验 | ["abc", "321"] |
| 对象 | 对象 | object | - | - |
| Json | - | object | 复杂的数据结构或动态属性 | { "title":"My First Blog Post","body": "<h1>Welcome to my blog!</h1><p>This is my first post.</p>","tags": ["blog", "first post","introduction"] } |
| 邮箱 | 邮箱 | string | 含有 xx@yy.zz | "email@qq.com" |
| 电话 | 固定电话 | string | 有0开头的2,3位区号或者没有区号的7-8位字符串 | "0271-1234567"或"027-1234567"或"1234567" |
| 手机号码 | string | 符合手机号规范的11位字符串 | "13812341234" | |
| 网址 | 网址 | string | 符合网址规范的字符串 | `https://xxx.xxx.xx` |
| 图片 | 图片 | string | 默认从前端组件获得图片的 cloudId | `cloud://xxx.xxx.xxx.png` |
| 多媒体 | 视频 | string | 支持类型:ogm、wmv、mpg、webm、ogv、mov、asx、mpeg、mp4、m4v、avi | cloud://xxx.xxx.xxx/xx.mp4 |
| 音频 | string | 支持类型:opus、flac、webm、weba、wav、ogg、m4a、oga、mid、mp3、aiff、wma、au | cloud://xxx.xxx.xxx/xx.wav | |
| 富文本 | - | string | 最长可存储262144字节 | - |
| Markdown | - | string | 可使用 Markdown 编辑器编辑内容,并支持实时预览 | # 这是一个Markdown示例 |
| 日期时间 | 日期时间 | number | 默认从前端组件获取的时间戳,单位为ms | 1645977600000 |
| 日期 | number | 默认从前端组件获取的时间戳,单位为ms | 1645977600000 | |
| 时间 | number | 默认从前端组件获取的时间戳,单位为ms | 1645977600000 | |
| 枚举 | 单选 | string | 所填值必须为用户设置的枚举值中的某一个,存储为字符串 | "牛奶" |
| 多选 | array | 所填值必须为用户设置的枚举值中的某一个或多个,存储为数组 | ["牛奶", "面包"] | |
| 地理位置 | - | object | 固定格式的对象,address 是位置的文字说明,coordinates 是包含经纬度的数组,详见传参示例 | {"geopoint": { "type": "Point", "coordinates": [ 40.56, 5.89]},"address": "深圳市南山区深南大道**号"} |
| 文件 | 文件 | string | 默认从前端组件获得文件的 cloudId | `cloud://xxx.xxx.xxx.png` |
| 自动编号 | - | string | 例如客户不填则后端自动补齐;例如客户传参,使用客户定义的值 | 1001 |
| 地区 | 省 | string | 无 | 陕西省 |
| 省市 | string | 以逗号分割的地理位置 | 陕西省,西安市 | |
| 省市区 | string | 以逗号分割的地理位置 | 陕西省,西安市,雁塔区 | |
| 关联关系(新) | 关联关系 | string | FLEXDB:支持一对一、一对多、多对一关联关系; MYSQL:支持一对一、一对多、多对一、多对多关联关系 | 详见本篇有关关联关系说明 |
字段通用配置
概念解释
字段名称:支持中英文。
字段标识:标识不能为空,不能以数字开头,只能包含字母、数字或_,不能输入超过40个字符。
数据类型:即字段类型选择,可参考字段类型设置所需字段设置。
是否必填:该字段是否必填。
是否唯一:该字段的取值是否允许重复,设置为唯一则不允许填重复值。
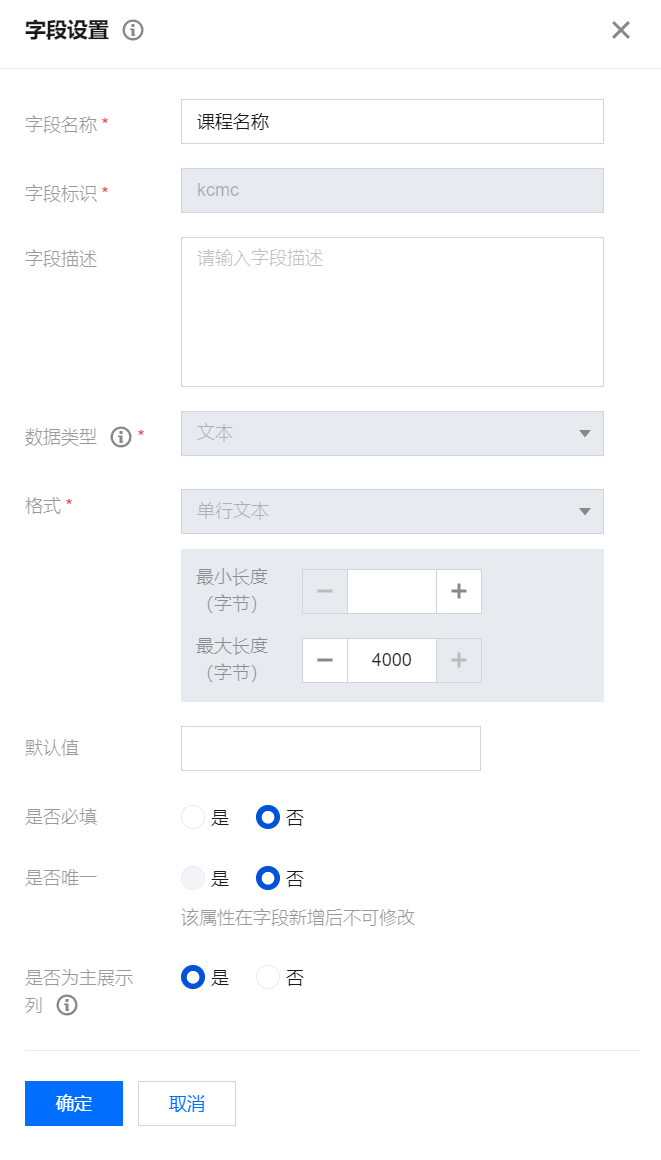
是否为主展示列:数据类型为文本 时可选择。当用户在其它数据模型中,配置关联关系或主子明细字段关联到本数据模型时,该字段会显示为主展示列的值,方便用户查看。此配置仅影响查看效果,不影响关联关系或主子明细字段实际存储内容。
主展示列详解
用户可以在数据模型中设置一个字段为主展示列。该字段将会影响其它模型关联此模型时的展示名称。下面以学生和课程两个数据模型为例,说明主展示列的使用方法。
学生模型配置:课程表数据类型为关联关系,关联的数据模型为课程。
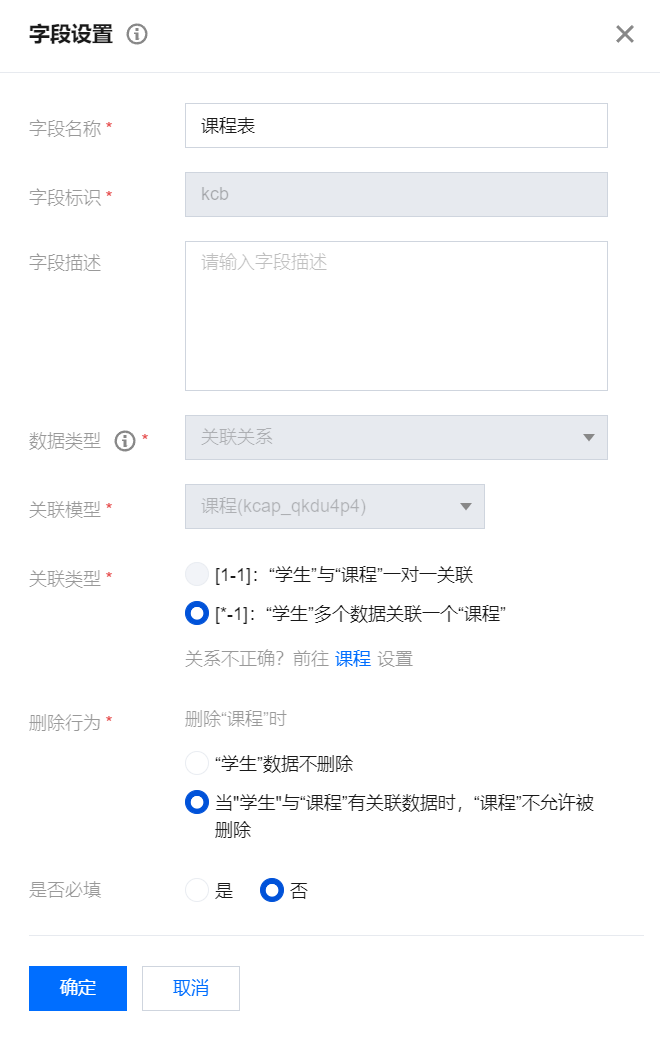
课程模型配置:课程名称设置为主展示列。
通过接口查询该数据模型结果如下:课程表字段实际存储的仍然是关联表的 id,通过 @kcb
返回了关联表中该条记录的全部内容,并通过"primaryColumn": "mc"标识出主展示列为哪个字段。
{
"records": [{
"xm": "张三",
"_id": "962d008f650404bc024c52f43a471189",
"kcb": "93e4b6a0640e9139042f27941b0ab7e6",
"@kcb": {
"v1": {
"primaryColumn": "mc",
"record": {
"owner": "1446845068964986882",
"createdAt": 1678676281098,
"createBy": "1446845068964986882",
"updateBy": "1443776918208724994",
"mc": "语文",
"_id": "93e4b6a0640e9139042f27941b0ab7e6",
"updatedAt": 1690341673543
}
}
}
},
{
"xm": "李四",
"_id": "41d77edc650404c8024ad4636a1c0704",
"kcb": "987a4537640e9140042d5c5715fce0ce",
"@kcb": {
"v1": {
"primaryColumn": "mc",
"record": {
"owner": "1446845068964986882",
"createdAt": 1678676288091,
"createBy": "1446845068964986882",
"updateBy": "1443776918208724994",
"mc": "数学",
"_id": "987a4537640e9140042d5c5715fce0ce",
"updatedAt": 1690341680970
}
}
}
}
],
"total": 2
}
在表格组件中,为方便用户查看,课程表字段自动转换为主展示列显示出来。
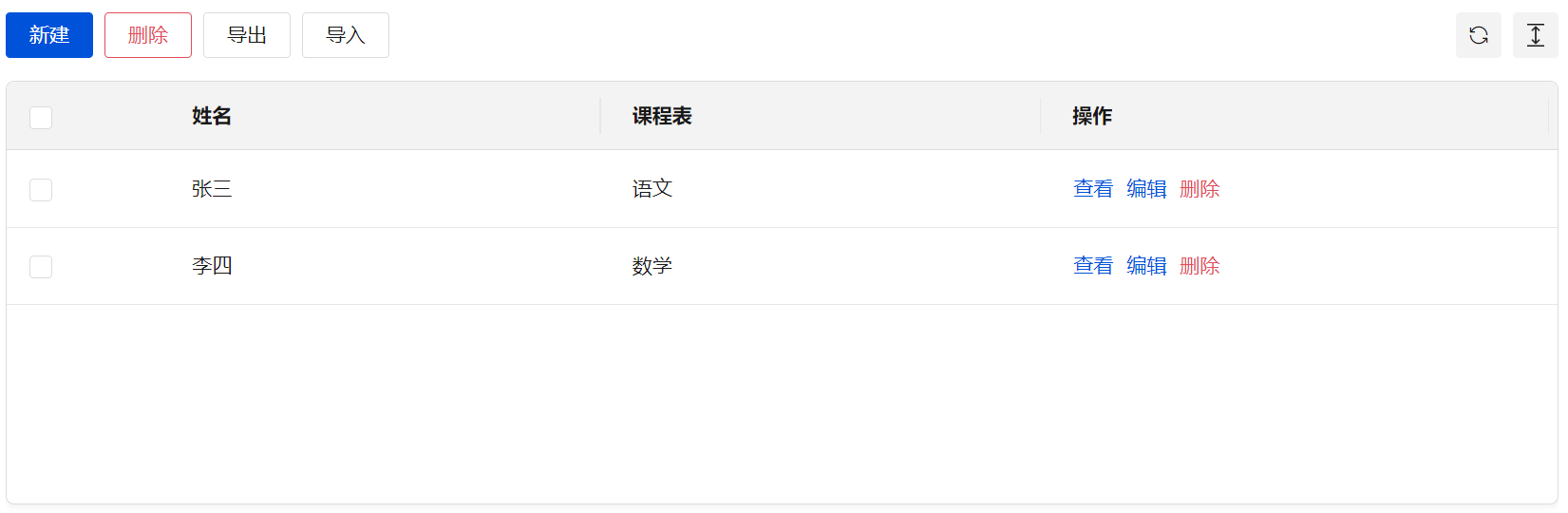
需要注意的是,如上文所述,该字段实际存储为记录的 id。
在使用数据筛选时,如果想查询课程表字段为语文的记录,筛选条件应使用课程模型中语文对应的 id 值。
{
"where": {
"$and": [{
"$and": [{
"kcb": {
"$eq": "93e4b6a0640e9139042f27941b0ab7e6"
}
}]
}]
}
}
在表单容器中,绑定学生模型时,课程表字段会自动生成为下拉单选组件。组件的选项名称即为主展示列,选项值为 id。
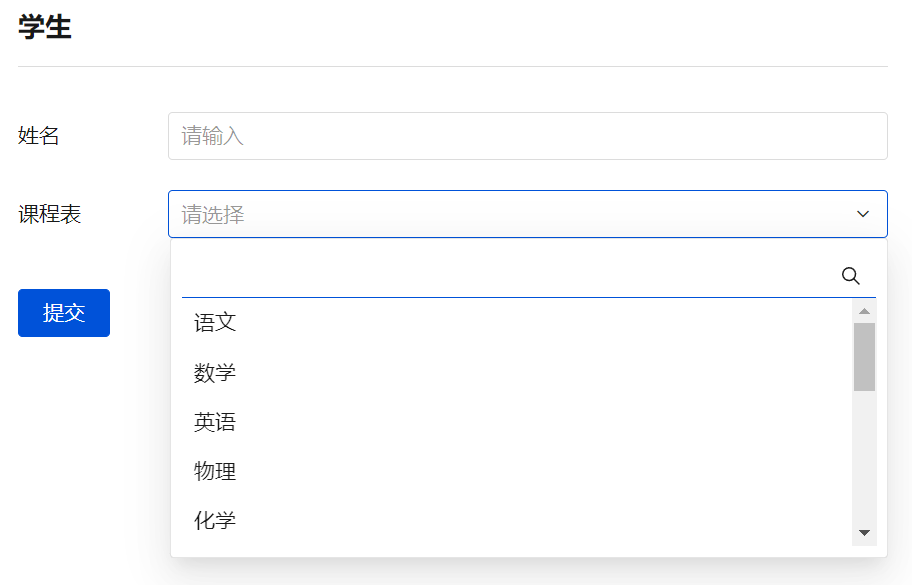
从提交的参数可以看出,课程表字段提交的是选项值,保存的是关联记录的 id。
{
"xm": "王五",
"kcb": "93e4b6a0640e9145042f2e635ed8600f"
}
字段使用说明
枚举
字段的是否枚举属性已升级为枚举字段,枚举字段属性设置参考:
选择设置:支持单选、多选。
单选:仅允许选择单个枚举值。
多选:允许选择多个枚举值。
关联选项集:枚举字段的枚举值依赖于通用选项集,当没有合适选项集时,可单击立即创建。
说明:
历史已经设置了是否枚举属性的字段仍可正常使用,官方建议升级为枚举类型字段。
计算公式
新增计算公式类型字段,选择结果类型。
结果类型支持文本、日期时间、数字。
输入计算表达式,表达式规则请参见 表达式。
自动编号
自动编号性质与字符串类型相同,只是在创建一条记录时,若用户没有输入值,则自动生成的指定格式的字符串值。开发者可以按其偏好自定义这些字段的格式,然后依靠系统在运行时生成自动填充它们的匹配值。 自动编号类型字段支持三种编号类型:字符串前缀、日期前缀、自定义。
字符串前缀
在该类型中,自动编号将包含自动递增的数字,具有可选的字符串常量前缀。
规则: {前缀}-{SEQNUM:最小位数+起始值}。
最小位数:自动生成的编号序列要包含的最小位数。随着编号序列继续增加,它可能比此最小值长。
起始值:用于自动编号列的序列号部分的起始值。
示例:前缀:CAR,最小位数:4,起始值:1000。
结果:CAR-1000,CAR-1001,CAR-1002,CAR-1003。
日期前缀
在该类型中,自动编号将包含自动递增的数字,具有确定格式的日期前缀。 行的日期部分将反映以 UTC 时间创建行的当前日期和时间。 内置供选择的不同日期格式,包含:
yyyy-MM-dd
MM-dd-yyyy
MM-dd-yy
dd-MM-yy
规则:{DATETIMEUTC:日期格式}-{SEQNUM:最小位数+起始值}。 举例:日期格式:yyyy-MM-dd,最小位数:4,起始值:1000。 结果:2010-01-01-0001,2010-01-01-0002,2010-01-01-03。
自定义
在该类型中,可能包括字符串常量、自动递增数字、确定格式的日期格或随机的字母数字序列。 单击添加格式可以向格式字段输入框文本后面插入默认格式。 支持的格式语法如下:
| 格式类型 | 语法示例 | 预览 | 默认添加格式 |
| 连续数字 SEQNUM | -CAR-{SEQNUM:3} | CAR-123 | {SEQNUM:4} |
| 时间日期 DATETIMEUTC | CAR-{DATETIMEUTC:yyyyMMddhhmmss} | CAR-20211223164721 | {DATETIMEUTC:yyyy-MM-dd} |
| 随机字符串 RANDSTRING | CAR-{SEQNUM:3}-{RANDSTRING:6} | CAR-123-AB7LSF | {RANDSTRING:4} |
说明:
自动编号类型的字段和其他类型字段功能一致。一样可以用于表单提交或用户自己输入值。唯一不同的是该字段设置成非必填的情况下,用户创建记录时又没有输入该字段的值,则按照指定格式填充数据。
用户自己填入值的时候,不占用自增序列值。即:自动创建了 1000, 1001后,用户新增一条 aaa 的值,再一次自动新增时为1002,不会产生序列中断。
说明:
自动编号类型字段在模型的方法中同数据标识(_id), 新增、更新方法的入参不包含自动编号类型字段,即不可新增或修改。